




Sommaire
- Introduction
- Le moteur du Machine Learning, son fonctionnement
- Les pilotes du Machine Learning, les Data Scientists
- Le carburant du Machine Learning, les données
- Le fuselage du Machine Learning, le design stratégique
- Les missions ou cas d’application du Machine Learning
- Focus sur une mission, l’assurance crédit
- Focus sur d’autres missions, maintenance prédictive, segmentation clients, systèmes de recommandation
Glossaire
Big Data : Le Journal Officiel du 22 août 2014 préconise d’utiliser en français le mot mégadonnées. Il en donne la définition suivante : données structurées ou non, dont le très grand volume requiert des outils d’analyse adaptés.
Data management platform (DMP) : appelée en français plateforme de gestion des données, elle sert à accumuler et à classer les données des internautes interagissant avec un site web pour ensuite permettre de mieux cibler les publicités en ligne.
Deep Learning : ou apprentissage profond. Famille de méthodes de Machine Learning, permettant un apprentissage automatique différent par niveau de détail, en utilisant des réseaux de neurones artificiels.
Hadoop : Plateforme d’analyse dédiée à l’analyse des Big Data, utilisant une technique dite de stockage et de calcul distribués.
Internet of Things (IoT): ou internet des objets (objets connectés). Cette expression représente l’extension du réseau internet à des objets (souvent des capteurs) ou des lieux. Les données transmises par ces objets doivent ensuite être analysées et corrélées à d’autres données, notamment à l’aide du Machine Learning.
Small Data : Il n’y pas de définition officielle pour les Small Data. C’est plutôt en opposition aux Big Data, les « petites » données qui concernent la vie de tous les jours de l’entreprise (ex : données des tickets de caisse, nombre de clients ayant pénétré dans le magasin…) et souvent non exploitées par les entreprises. Dès lors que ces données sont exploitées et que leur utilité est avérée, ces petites données devenues « intelligentes » sont souvent appelées Smart Datas.
Stratégie SEA (Search Engine Advertisement): ou référencement payant, elle consiste à la mise en place de réponses payantes dans les pages de résultats d’un moteur de recherche.
Introduction
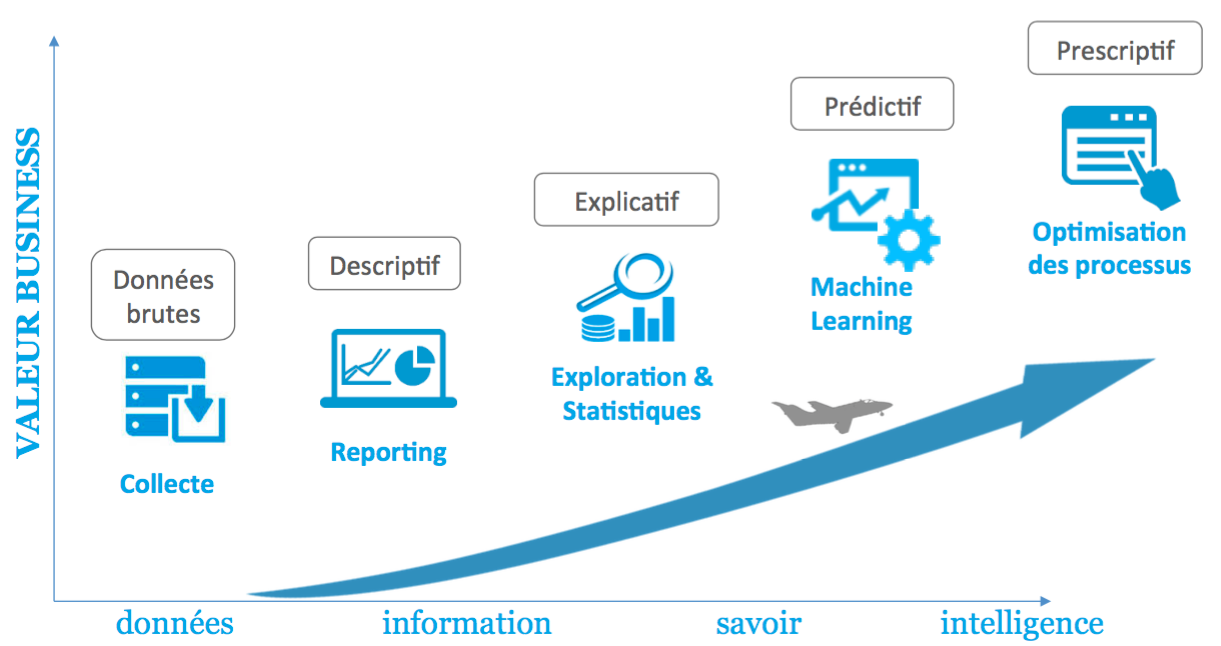
L’expression de « Machine Learning », ou en français, apprentissage automatique, aussi appelée « analyse prédictive » ou parfois « intelligence artificielle » connaît aujourd’hui un développement très important, tant dans le monde des entreprises qu’auprès du grand public.
Le Machine Learning est en effet ce qui donne de la valeur aux données et permet de faire décoller les projets Big Data des entreprises. Le Machine Learning désigne une technique informatique qui permet d’obtenir des prédictions à partir de données brutes. Cette définition peut paraître floue et mystérieuse, mais loin de la magie, il y a derrière cette technique, de puissants outils statistiques. Leur explication permet alors d’en comprendre tout l’intérêt ainsi que la manière de le mettre en œuvre dans le contexte de chaque entreprise.
Nous allons exposer dans ce livre blanc :
• ce qu’est précisément le Machine Learning,
• ses possibilités,
• ses limites,
à travers plusieurs cas d’applications :
• la prédiction des prix dans l’immobilier,
• le traitement des demandes de remboursement dans l’assurance crédit,
• la maintenance prédictive dans l’industrie,
• la segmentation clients,
• les systèmes de personnalisation et recommandation.
Ces cas d’application montrent notamment comment le Machine Learning peut venir apporter de la valeur aux applications business et tirer vers le haut toute la stratégie digitale d’une entreprise.
McKinsey Quarterly, Juin 2015
Une douzaine de banques européennes ont récemment remplacé leurs approches statistiques traditionnelles par des techniques de Machine Learning, notamment par des nouveaux systèmes de recommandation. Dans certains domaines, elles ont obtenu, grâce à ces nouvelles techniques, des résultats impressionnants, comme une hausse de 10% de vente de nouveaux produits, 20% d’économies en dépenses d’investissement, une hausse de trésorerie de 20% et une baisse de 20% de désabonnements.
Le moteur du Machine Learning
Issu d’idées plus anciennes, le Machine Learning a réellement commencé à se développer dans les années 1990 sur des « small data », limité par les capacités de stockage et de calcul de l’informatique de l’époque. Depuis la fin des années 2000, on assiste à une explosion de son utilisation combinée aux techniques de Big Data, pour prédire toute sorte d’informations vitales aux entreprises et apporter ainsi de la valeur à leurs données. Le Big Data permet en effet de démultiplier la puissance prédictive du Machine Learning.
Pour aller à l’essentiel, le Machine Learning consiste en la combinaison de l’efficacité des modèles statistiques à décrire la réalité avec la puissance de traitement et d’automatisation de l’Informatique.

C’est la seule équation à retenir de ce livre blanc ! Ainsi le Machine Learning développe des algorithmes qui vont apprendre de manière automatisée des modèles statistiques à partir de données d’apprentissage. Ceci peut se faire de manière supervisée, non supervisée, par renforcement… Il y a beaucoup de méthodes mais nous allons nous concentrer sur un des mécanismes de base qui concerne l’apprentissage supervisé.

Prenons l’exemple de l’immobilier. A partir des caractéristiques d’une maison (surface, nombre de chambres, de salles de bain, jardin, vue, année de construction, localisation…), on souhaite prédire par le Machine Learning quel sera son prix de vente, de manière bien plus précise que juste avec le prix du mètre carré.
On fournit donc à la machine une base de données des ventes de maisons réalisées dans la région cible (potentiellement des milliers de vente), qui contient pour chaque maison toutes ses caractéristiques (potentiellement des centaines) ainsi que les prix de vente réellement enregistrés.
ID | Prix de vente | Surface habitable | Nb de chambres | Nb de salles bain | Année de construction | Localisation |
Maison1 | 201000 | 63 | 2 | 1 | 1965 | CV |
Maison2 | 569000 | 120 | 5 | 2 | 1986 | B |
La machine considère itérativement chaque maison de la base de données :
1. elle en extrait les caractéristiques,
2. elle les fait passer dans un modèle de Machine Learning, ici appelé Régression,
3. le modèle prédit alors un prix de vente pour cette maison.
4. La machine compare le prix prédit avec le prix réel (dans la base de données).
5. Elle ajuste en conséquence les coefficients décrivant le modèle de Machine Learning (Régression) grâce à un algorithme spécial pour améliorer cette comparaison.
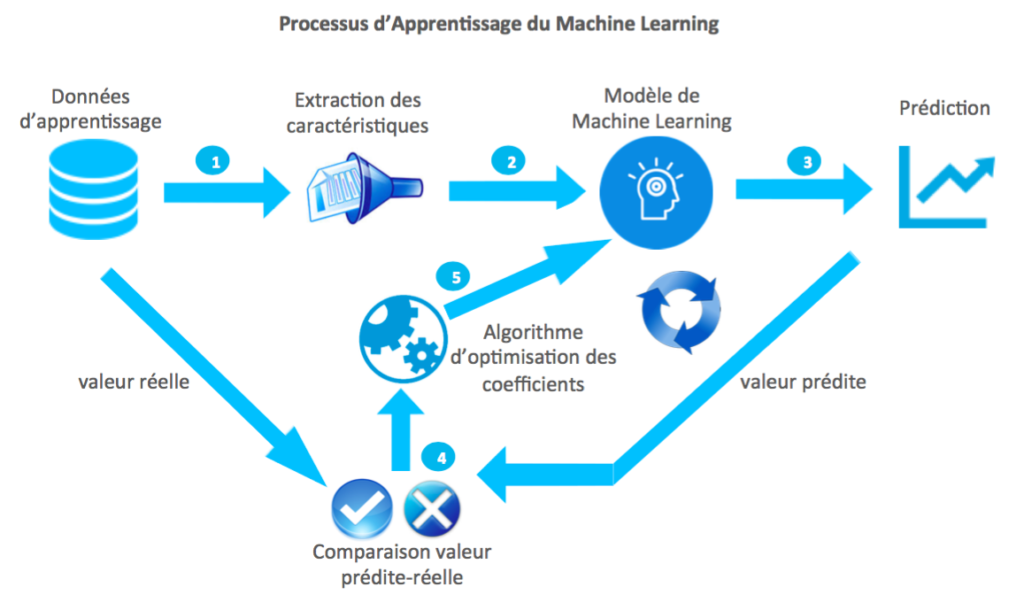
Le modèle de Machine Learning, via ses coefficients, évolue donc itérativement, à chaque fois qu’une maison de la base de donnée est analysée. A la fin, il est optimisé pour que la comparaison des prix prédits avec les prix réels sur toute la base de données des maisons soit la meilleure possible. On dit que la machine a appris le modèle, en étant supervisée car les réponses (prix de vente réels) lui étaient fournies. A ce moment-là, on peut fournir à la machine des caractéristiques de maisons dont on ne connaît pas le prix de vente, et le modèle permet alors de le prédire.


Les pilotes du Machine Learning
Examinons maintenant le profil de ceux qui construisent des modèles de Machine Learning. A côté des deux autres profils techniques mis en jeu par le processus Big Data – les Data Strategists et les Data Architects – le Data Scientist définit, met en place et pilote le modèle de Machine Learning pertinent sur une plateforme d’analyse mise à sa disposition. Voici le détail des compétences qu’il doit maîtriser.
Positionné auprès des Métiers, le Data Scientist exploite, analyse et évalue la richesse des données existantes pour établir des scénarios Machine Learning permettant de comprendre et d’anticiper de futurs leviers métiers ou opérationnels.
• Il doit comprendre les aspects et contraintes Métiers des données qu’il manipule pour en extraire des analyses pleinement utiles au client.
• Il doit savoir manipuler les données à analyser, c’est-à-dire posséder de bonnes connaissances ETL – extraction, transformation, chargement (load en anglais) – et pouvoir assurer un nettoyage méthodique des données pour une utilisation optimale du Machine Learning.
• Il doit maîtriser les théories mathématiques et statistiques qui sous-tendent les modèles de Machine Learning qu’il met en œuvre, afin d’en connaître au mieux la pertinence et les limites.
• Le Machine Learning étant le procédé d’apprentissage de la machine, le Data Scientist met en œuvre ses modèles au moyen de code informatique. Il doit donc maîtriser les langages informatiques et les librairies associées qui lui permettront de coder ses algorithmes sur différents types de plateformes analytiques.
• Enfin, l’analyse des données permet l’aide à la décision. Le Data Scientist doit donc posséder de fortes compétences en visualisation des données ainsi qu’en présentation des résultats de ses analyses. Pour faire passer un message de manière optimale, les meilleures pratiques de visualisation mènent à l’intégrer au sein d’une histoire (storytelling) qui permet d’en gommer le côté technique et de le personnaliser.


Etape stratégie : Le processus Big Data commence par une réflexion stratégique de l’entreprise concernant l’utilité et la valeur que va apporter l’analyse prédictive à son business. De cette réflexion, qui peut être accompagnée par des experts, découle une identification des sources de données pertinentes pour l’algorithme de Machine Learning, internes ou externes, leur type (structuré ou non), leur importance relative, leur difficulté et coût de récupération. Cette phase est dirigée par le Data Strategist dont nous parlerons ci-dessous.

Etape architecture :
Compte-tenu de la stratégie définie, on dessine alors une architecture de base de données, support des analyses à effectuer pour l’entreprise client. Cette architecture comprend :
• le design de la plateforme d’analyse Hadoop et de stockage (dans le Cloud / on Premise) en tenant compte des besoins du client en terme de sécurité, d’accès et de gouvernance des données,
• l’extraction des données brutes à partir des sources identifiées,
• le nettoyage automatique et le chargement de ces données sur la plateforme,
• la prise en compte des résultats d’analyse dans des outils de reporting et de visualisation pour l’aide à la décision du client.
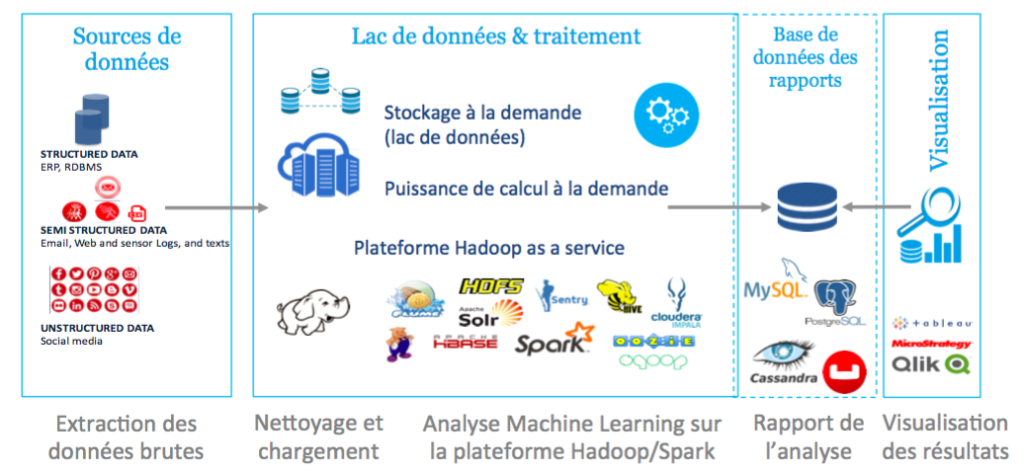
Cette étape, réalisée par le Data Architect, est cruciale à la fois pour la qualité des données utilisées par le modèle de Machine Learning – le nettoyage des données correspondant au raffinage du carburant du modèle – mais aussi pour permettre un fonctionnement rapide et optimisé des algorithmes utilisés sur la plateforme analytique. L’étape d’architecture correspond ainsi au raffinage du carburant et à la mise en place d’un système d’injection rapide pour le moteur qu’est le Machine Learning.

Etape analyse : Une fois la plateforme construite, le pilote, ou Data Scientist, dont nous avons étudié le profil ci-dessus, peut alors tester différents modèles de Machine Learning pour l’analyse souhaitée par l’entreprise et déployer le plus adapté et efficient.

Le fuselage du Machine Learning
Comme nous l’avons vu ci-dessus, la machine ingère les données pour en extraire des caractéristiques qui vont être directement corrélées à la valeur à prédire. Les données correspondent donc au carburant faisant fonctionner un modèle de Machine Learning. Ainsi, la pertinence des caractéristiques, leur qualité et leur quantité sont des critères déterminants pour la précision des prédictions du modèle. C’est pourquoi le Machine Learning est souvent considéré dans une démarche globale d’architecture et d’analyse Big Data (c’est notamment l’approche de Myriad !), que nous allons brièvement décrire.
Comme le commandant d’escadrille, le Data Strategist établit le plan de vol pour la mission, gère les interactions avec les autres missions, ainsi qu’avec les pilotes et le Top Management de l’entreprise. Il doit avoir une très bonne capacité d’adaptation et une connaissance Métiers pour comprendre tous les enjeux de la mission et pouvoir les traduire en termes techniques ou opérationnels pour les pilotes. Son rôle est capital dans l’approche sur-mesure du Machine Learning : il choisit le design stratégique du Machine Learning dont ont besoin vos métiers, que les Data Scientists vont ensuite décliner et utiliser.
Le Data Strategist doit être conscient des possibilités comme des limites du Machine Learning et de ses pilotes. Il doit notamment trouver un compromis entre la performance des algorithmes et la complexité de leur mise en œuvre. Illustrons ceci par un exemple. L’entreprise Netflix a offert un prix d’un million de dollars en 2006 pour diminuer l’erreur de leur modèle de Machine Learning de 10%. Cela a été réalisé en 2009, mais le modèle gagnant fut finalement trop compliqué à implémenter en production et surtout il fut impossible d’assurer sa maintenance opérationnelle, et donc il ne fut pas utilisé. Voici une des limites du Machine Learning, concernant sa mise en production, que doit parfaitement maîtriser le Data Strategist.
Approche sur-mesure
Le design sur-mesure de l’algorithme de Machine Learning en fonction du résultat souhaité ou de la mission demandée est un atout stratégique. C’est un principe général de la Physique que le modèle mathématique doit s’adapter à la réalité qu’il doit décrire, et non l’inverse. Pour les données, le principe reste le même: l’algorithme doit s’adapter au résultat souhaité et aux données fournies, et non l’inverse. Ainsi, suivant la qualité des données (fiabilité des sources, nettoyage et filtrage, standardisation), l’architecture déjà existante, les profils de Data Scientists disponibles pour la mission, les contraintes légales et sécuritaires, les attentes des métiers, se met en place un profil de mission très spécifique et adapté : c’est au Data Strategist de le déterminer.

Finance – Assurance
• Modélisation d’indicateurs économiques
• Personnalisation de l’expérience client
• Evaluation de la solvabilité de l’emprunteur
• Détection de fraudes
• Analyse de marché et benchmarking
Marketing digital
• Segmentation clients au sein de DMP (data management platform)
• Analyse multicanal
• Scoring des prospects
• Optimisation de stratégies SEA (Google AdWords)
E-commerce
• Analyse de paniers
• Personnalisation de recommandations produits
• Analyse de sentiment sur les réseaux sociaux
• Evaluation de la satisfaction client
• Ventes additionnelles et ventes croisées
Industrie
• Maintenance prédictive sur les données d’objets connectés (IoT)
• Détermination et ajustement de prix
• Prévision des stocks
• Relations clients (CRM)
• Surveillance de la réputation sur internet
Ressources humaines
• Automatisation de recherche de profils (avec le Natural Language Processing)
• Evaluation des risques de départs
• Optimisation du marketing de recrutement
Energie,
transport,
luxe,
telecom…


Enjeux initiaux du client :
L’assurance XCC1, de crédit à la consommation, rembourse le crédit de l’emprunteur dans les cas suivants : décès, invalidité ou perte de travail, suivant le contrat établi avec l’emprunteur. Or depuis l’application de la loi Hamon en 2015, le marché de l’assurance crédit est soumis à une forte pression concurrentielle due aux facilités pour l’emprunteur de changer d’assurance crédit notamment pendant la première année de son emprunt.
Dans ce contexte, l’assurance XCC devait faire face à un fort enjeu concernant le délai des demandes de remboursement. En moyenne, un emprunteur faisant une demande de remboursement voyait son dossier traité en 5 mois. Ceci engendrait bien évidemment une frustration du client, ce qui se reflétait en particulier sur internet. Un rapide audit interne permit de déterminer les grandes causes de cet état de fait :
1. Une mauvaise gestion de la récupération des données (formulaires, certificats,) au moment des demandes de remboursement.
2. Des données non centralisées, notamment entre les données clients récupérées au moment de la signature du contrat, et celles des demandes de remboursement. Ceci engendre une perte de temps pour les agents d’assurance devant traiter le dossier.
3. Des effectifs réduits de moitié par rapport à un traitement optimal. Les agents d’assurance précités font alors face à une surcharge de travail et de stress, ce qui augmente mécaniquement les délais de traitement mais aussi les erreurs de traitement.
Face à ces enjeux, l’assurance XCC aurait pu opter pour la solution classique, à savoir le doublement de ses effectifs d’agents dédiés au traitement des demandes de remboursement. Mais elle lui a préféré un projet Big Data exploitant la puissance du Machine Learning.


Afin de déterminer le retour sur investissement de la partie centrale de ce projet, à savoir l’automatisation du traitement des demandes de remboursement par le Machine Learning (algorithme de Classification), l’entreprise Myriad a réalisé un PoC (test) sur un échantillon des données de l’assurance XCC. Nous présentons ici les résultats, très parlants, de ce PoC.
Résultats du PoC :
Deux scénarios d’automatisation de traitement des demandes de remboursement ont été déterminés :
• le premier focalisé sur l’accélération des remboursements, où on impose un pourcentage de plus de 75% d’automatisation ;
• le second sur une réduction optimale des coûts, et qui obtient alors une automatisation de 55% des demandes de remboursement.
Il est à noter que les coûts de traitement mensuels prennent en compte le coût salarial des effectifs dédiés à la vérification manuelle des demandes de remboursement ainsi que le coût dû aux erreurs de traitement (remboursements indus). Voici le tableau de bord obtenu pour ces deux scénarios (vert et bleu), en comparaison avec la solution sans Machine Learning de doublement des effectifs (rouge) :
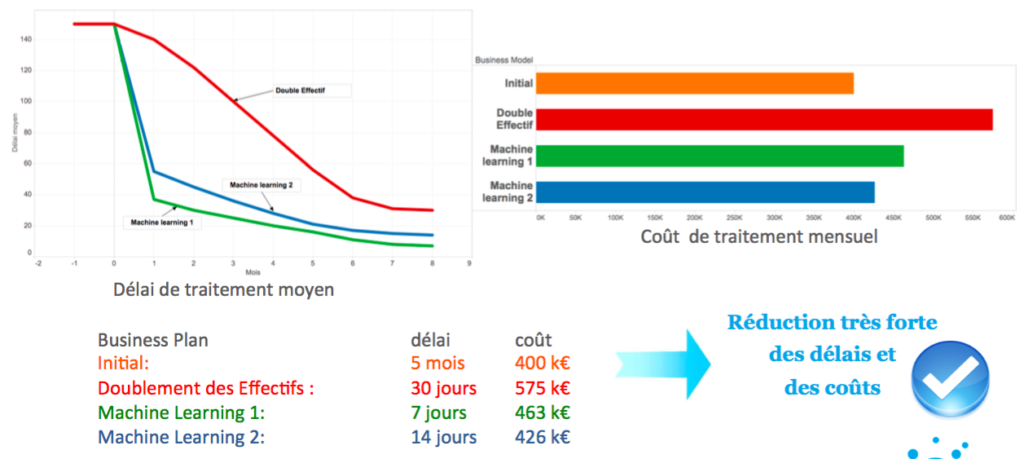
Scénario 1 :
On remarque qu’en imposant une forte accélaration du traitement des demandes de remboursement (scénario 1), on diminue les délais moyens de remboursement de manière drastique, à 7 jours. Le coût de traitement mensuel, réduit de 20% par rapport au doublement des effectifs, inclue alors une très faible part due aux effectifs (vérification manuelle de seulement 20% des dossiers), mais il y a une partie importante due à l’erreur statistique de l’algorithme. Cette erreur pourrait être réduite significativement, ainsi que les coûts, en ajoutant en amont une phase de nettoyage des données, non incluse dans ce PoC. En effet, environ un tiers des données n’était pas exploitable pour cause de donnée manquante, non standard…
Scénario 2 :
Le deuxième scénario s’est concentré sur une optimisation des coûts, avec notamment une réduction de 26% de ces coûts par rapport au scénario de doublement des effectifs et un délai moyen de traitement de 14 jours. L’erreur de traitement est alors proche de celle du scénario initial, bien que celle-ci puisse encore être réduite par un nettoyage des données comme mentionné ci-dessus. Comme 55% des dossiers sont traités automatiquement, il reste 45% de vérifications manuelles. Ceci donne un effectif proche de celui du scénario initial, mais avec cette fois-ci une charge de travail optimale et non pas double.
Cet exemple de l’assurance crédit montre qu’avec un coût de mise en place faible devant les coûts de traitement mensuel, le Machine Learning peut aider l’assurance XCC dans l’automatisation du traitement de ses demandes de remboursement en améliorant ses statistiques de façon impressionnante : 26 % de réduction des coûts, et
diminution des délais de moitié.
Focus sur d’autres missions
Après avoir vu de manière approfondie la méthodologie de mise en place du Machine Learning dans le cadre de l’assurance crédit, ainsi que les résultats chiffrés que cela produit, nous allons étudier de manière plus synthétique d’autres cas d’usage dont nous ne décrirons que la partie spécifique.
Maintenance prédictive
Dans le secteur de l’industrie, l’utilisation du Machine Learning vient à se généraliser pour la maintenance prédictive. On connecte des dizaines de capteurs sur la chaîne de production mesurant les différents signaux pertinents relatifs au bon fonctionnement de la chaîne.
Puis l’utilisation de l’historique des données de cette chaîne de production, et notamment de son état de fonctionnement, permet d’entraîner un modèle de Machine Learning appelé Régression. Celui-ci peut ensuite :
• diagnostiquer en temps réel l’état de fonctionnement de la chaîne de production,
• analyser les risques futurs de défaillance technique et identifier sur quelle pièce,
• déterminer en conséquence un plan de maintenance prédictive de la machine en minimisant son temps d’arrêt.
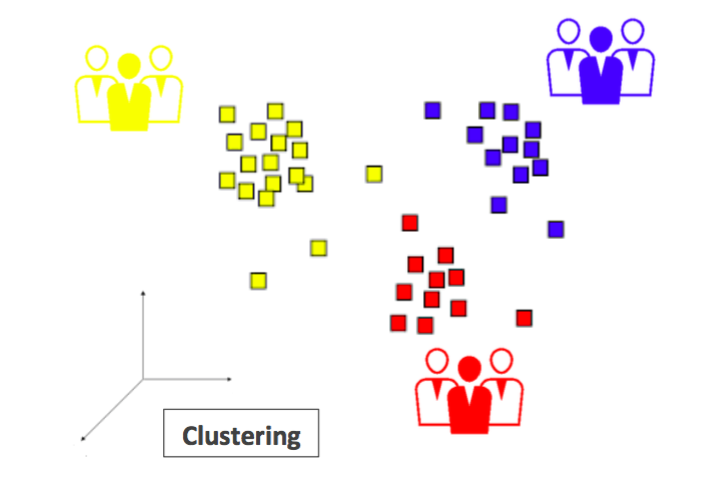
Segmentation clients
La segmentation des clients est un élément clé du marketing dans le secteur du commerce électronique : elle permet de regrouper dans diverses catégories des consommateurs aux comportements similaires et d’analyser ces comportements pour ensuite optimiser les recommandations des produits, les campagnes marketing, et ainsi les ventes de l’entreprise.
Cette segmentation clients peut se faire au sein d’une plateforme de gestion de données (DMP) ou avec des algorithmes spécifiques adaptés au client. Le modèle général de Machine Learning utilisé s’appelle le Clustering, qui est un exemple d’apprentissage non supervisé, contrairement aux modèles (Classification, Régression) que nous avons vus ci-dessus.
Dans l’espace multi-dimensionnel de toutes les caractéristiques des consommateurs (par exemple, la fréquence des achats, le prix moyen des achats, la réactivité face aux produits recommandés, l’appartenance au programme de fidélité, les informations démographiques comme lieu, âge, sexe… potentiellement des centaines de caractéristiques), chaque consommateur est représenté par un vecteur. Une distance adaptée au type de segmentation voulue permet alors de regrouper les vecteurs « proches », d’obtenir des catégo-
ries de consommateurs et d’analyser toutes leurs caractéristiques communes.
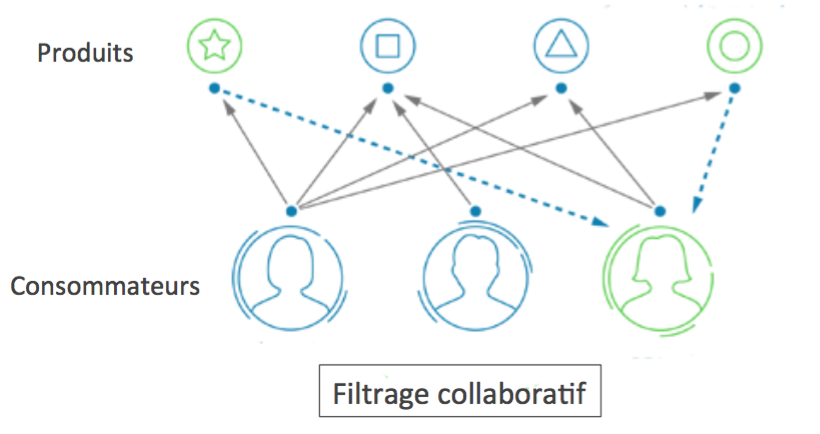
Système de personnalisation et recommandation
D’autres techniques de Machine Learning sont utilisées dans le cas des systèmes de recommandation ou de personnalisation par l’industrie, l’e-commerce, le luxe, la grande distribution… ainsi que par les réseaux sociaux comme LinkedIn et Facebook. Ces techniques avancées se nomment filtrage collaboratif ou factorisation de matrices. A titre d’illustration, voyons comment fonctionne le filtrage collaboratif dans le cas de la recommandation de produits.
Dans ce qu’on appelle une matrice de co-occurrence, on repère toutes les paires de produits qui sont fréquemment achetés ensemble. Puis, par un algorithme statistique, on en déduit une distance entre les produits codant cette appétence à être achetés ensemble. La machine détermine alors, pour chaque consommateur ayant acheté un produit particulier, quel serait le produit le plus pertinent à lui recommander, c’est-à-dire celui minimisant la distance avec le produit déjà acheté.
Certaines grandes marques de e-commerce ont ainsi pu améliorer leurs ventes de 30% en utilisant des systèmes de recommandation faisant notamment intervenir du filtrage collaboratif.
Axel de Goursac est directeur des opérations de Myriad. Après avoir été diplômé de l’Ecole Polytechnique et de l’Ecole Normale Supérieure de Paris, il a soutenu en 2009 une thèse de doctorat en Mathématiques et Physique aux Universités de Paris-Sud et de Münster (Allemagne). Puis, il a obtenu un poste de manager de projets de recherche à l’Université Catholique de Louvain et au Fond National de la Recherche scientifique (FNRS, Belgique) en Mathématiques et applications. Passionné de science et de technologie, il est également un chercheur internationalement reconnu et un expert en Machine Learning. Il dirige maintenant le département opérationnel de Myriad, ses Data scientists, architects et strategists.
Myriad est une société de service qui assure le conseil et le déploiement de solutions Big Data. Myriad offre aux Entreprises une véritable expertise dans les domaines analytiques, de Science des Données et d’Architecture. Aujourd’hui, les sociétés reconnaissent qu’il est nécessaire de s’affranchir d’une organisation des données en silos pour en révéler la valeur. Cela suppose de mettre en place une source unique pour les données de l’entreprise, qu’elles soient ou non structurées. Myriad accompagne ses clients dans le cadre de leur transformation vers le Big Data et leur fournit une assistance globale pour l’implémentation de cette transformation, allant d’une stratégie de données claire au Machine et Deep Learning.
Sa spécificité réside à la fois dans une approche sur-mesure, de haut niveau technique, mais aussi résolument orientée business, ainsi que sur une méthode progressive claire “Découvrir/Concevoir/Déployer”, qui permet à ses clients d’avoir le contrôle total de leurs initiatives Big Data. Pour assurer la maîtrise des Coûts et du ROI, une approche progressive basée sur des cas d’utilisations réels définis par les métiers est essentielle pour Myriad. Cette approche est un élément clé pour comprendre le business de ses clients, leur permettre de rester à la pointe et élaborer une carte numérique qui transforme leurs données en un véritable avantage compétitif durable.