




Sommaire
- Introduction
- Le NLP. Qu’est-ce ?
- Le NLP. Comment ça fonctionne ?
- Le NLP. Qu’est-ce que ça peut faire ?
- Le NLP. Comment ça s’applique pour l’entreprise ?
Glossaire
Big Data : Le Journal Officiel du 22 août 2014 préconise d’utiliser en français le mot mégadonnées. Il en donne la définition suivante : données structurées ou non, dont le très grand volume requiert des outils d’analyse adaptés.
Deep Learning : ou apprentissage profond. Famille de méthodes de Machine Learning, permettant un apprentissage automatique différent par niveau de détail, en utilisant des réseaux de neurones artificiels.
Small Data : Il n’y pas de définition officielle pour les Small Data. C’est plutôt en opposition aux Big Data, les « petites » données qui concernent la vie de tous les jours de l’entreprise (ex : données des tickets de caisse, nombre de clients ayant pénétré dans le magasin…) et souvent non exploitées par les entreprises. Dès lors que ces données sont exploitées et que leur utilité est avérée, ces petites données devenues « intelligentes » sont souvent appelées Smart Datas.
Machine Learning : ou apprentissage machine. Technique combinant la combinaison de l’efficacité des modèles statistiques à décrire la réalité avec la puissance de traitement et d’automatisation de l’Informatique. La machine va donc « apprendre » son propre modèle prédictif en s’entraînant sur des données d’apprentissage. Cf le Livre Blanc Myriad 2016 « Le Machine Learning, Envol vers le Prédictif » pour plus de détails.
Intelligence Artificielle : Il existe plusieurs définitions différentes de l’Intelligence Artificielle, mais dans sa déclinaison actuelle au service des entreprises, on peut dire qu’elle correspond à des techniques informatiques permettant de réaliser des tâches, nécessitant des capacités de réflexion ou de calcul avancées pour des humains. Celle-ci contient notamment le Machine Learning, le Natural Language Processing, la Computer Vision…
Introduction
L’Intelligence Artificielle, en tant que partie prenante du processus de digitalisation de l’entreprise, connaît un essor impressionnant sur grand nombre de secteurs d’activité et ses cas d’application se multiplient. Un des grands axes de développements de l’IA est constitué par la prise en compte et la mise en valeur des données non structurées autrefois peu utilisées. Une grande partie de ces données non structurées sont au format de textes, comme
• Le contenu des sites internet et leurs métadonnées
• Les messages des réseaux sociaux
• Les logs des machines
• Les emails
• Les articles, documents, présentations au sein d’une entreprise
• Les livres publiés
Aujourd’hui, l’Intelligence Artificielle peut venir enrichir les capacités d’une entreprise en tirant partie de ces données textuelles, grâce à une technique appelée « Natural Language Processing » ou Traitement Automatique du Langage Naturel.
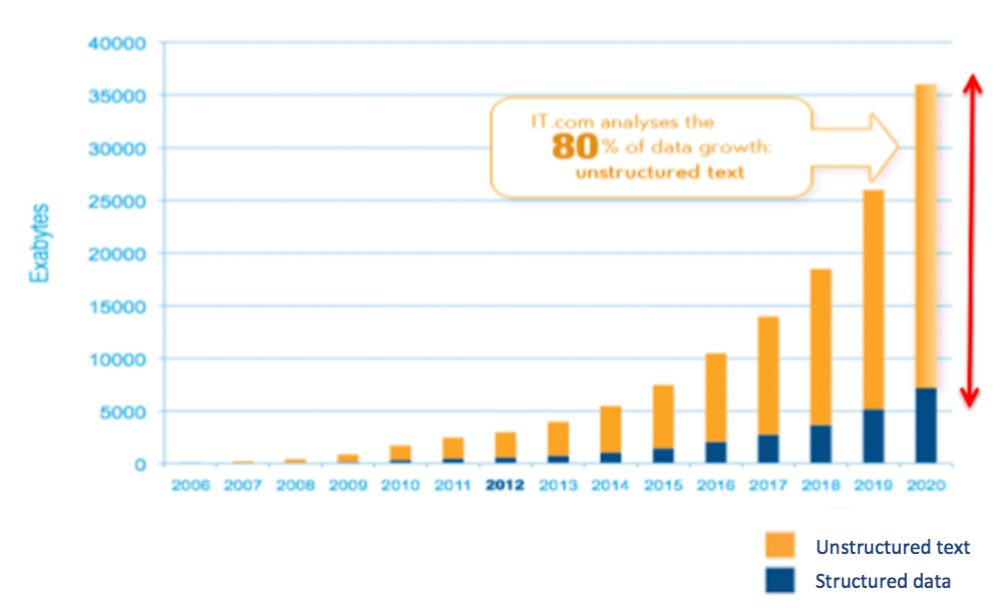
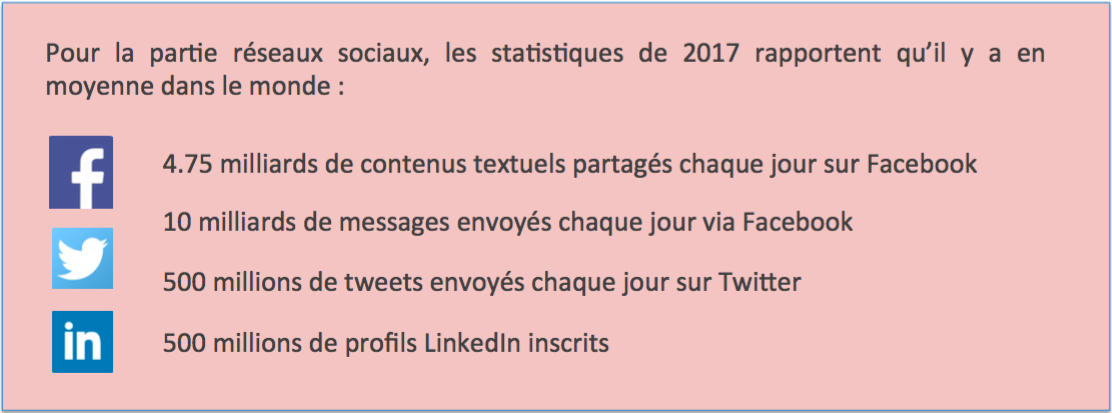
Pour donner un ordre de grandeur de l’importance des données textuelles, nous pouvons voir la projection ci-dessous de la croissance mondiale des données d’entreprise (Source : IDC, The Digital Universe 2010), ainsi que les statistiques des données de réseaux sociaux.
De manière simplifiée, on peut dire du NLP qu’il correspond à la partie textuelle/linguistique de l’Intelligence Artificielle. Or le texte/langage est justement le moyen d’expression naturelle de l’homme. C’est en cela que le NLP constitue la technique permettant une interface interactive entre l’humain et la machine.
Etant donné l’intérêt actuel du NLP, nous allons exposer dans ce livre blanc ce qu’est précisément le Natural Language Processing, les modèles sous-jacents, ses possibilités et ses limites, et présenter plusieurs cas d’applications :
• gestion des compétences dans le domaine RH
• maintenance dans l’industrie
• analyse de commentaires pour le Retail
• domaine juridique pour la conformité produit
Ces cas d’application montrent à quel point le Natural Language Processing peut valoriser des données textuelles souvent peu utilisées.
McKinsey Report, Mars 2017
L’automatisation des processus intelligents (IPA), qui regroupe entre autres le NLP et les agents cognitifs, fera partie intégrante des modèles d’exploitation de prochaine génération des entreprises. De nombreuses entreprises de tous les secteurs ont expérimenté cette technologie, avec des résultats impressionnants:
• Automatisation de 50 à 70% des tâches
• ce qui se traduit par des économies annuelles de 20 à 35%
• et une réduction du temps de traitement direct de 50 à 60%
avec, au total, un retour sur investissement le plus souvent en pourcentages à trois chiffres.
Définition
Le Traitement Automatique du Langage (ou « Natural Language Processing » en Anglais) correspond à un cycle automatisé par l’informatique de lecture/correction/analyse de données textuelles pour en retirer différents types d’information. Une de ses déclinaisons fréquemment utilisées pour la recherche de données s’appelle le « Text Mining ». De plus, le Traitement Automatique du Langage est de nos jours souvent supporté par des algorithmes d’Intelligence Artificielle ou Machine Learning.
Point de vue du type d’information considéré dans le texte.
Un texte est une donnée très riche, qui contient beaucoup d’informations sous la forme synthétique d’une chaîne de caractères que sont les lettres, les chiffres ou autres symboles. Il est en effet rédigé/prononcé par une personne dans un style particulier, il dépend d’un contexte donné ainsi que de la langue et de la culture de la personne, et il vise à exprimer et transmettre un contenu objectif sur des événements extérieurs, ce contenu étant souvent accompagné d’une opinion plus subjective de cette personne.
Ainsi, suivant le type d’information que l’on souhaite extraire d’un texte, le NLP va permettre d’acquérir
• de la connaissance sur le langage utilisé en lui-même (orthographe, grammaire, sens et connotations des mots…)
• de la connaissance sur le contenu du texte (le message que la personne veut faire passer)
• de la connaissance sur la personne à l’origine du texte (style, sentiments…)
• de la connaissance sur la réalité extérieure (fiabilité et adéquation du message à l’environnement décrit)
Point de vue du mode d’application du traitement effectué.
Le but du NLP est d’arriver à extraire les différents types de connaissance décrits ci-dessus de manière automatique grâce à l’informatique. Ceci peut se faire suivant deux modes :
• L’automatisation peut être déterministe. C’est-à-dire que les programmeurs vont implémenter des règles métiers bien définies pour le traitement et l’analyse des données textuelles. Cela peut concerner la correction orthographique ou l’identification de mots-clés (par exemple des villes ou des entreprises) à l’aide d’un référentiel prédéfini et par des techniques dites « d’expressions régulières ».
• Ou l’automatisation peut être statistique. Ce mode utilise alors des algorithmes auto-apprenants, c’est-à-dire qui vont apprendre les règles métiers de traitement et d’analyse eux-mêmes grâce à des lois statistiques. Ces algorithmes relèvent du Machine Learning, du Deep Learning et plus largement de l’Intelligence Artificielle.
Les modèles du NLP
Après avoir présenté les différents points de vue sous lesquels considérer les données textuelles et donc le NLP, nous pouvons maintenant examiner de façon plus technique quelles sont les technologies, ou les classes de modèles, sous-jacentes au NLP. On divise celles-ci en fonction de la représentation du texte utilisée.

Cette liste n’est bien sûr pas exhaustive mais rassemble un échantillon représentatif des modèles utilisés en NLP à l’heure actuelle.
1. Expressions régulières.
Comme nous l’avons déjà mentionné ci-dessus, les expressions régulières constituent un mode d’application déterministe du NLP. Les expressions régulières fournissent en effet une méthode puissante, flexible et efficace mais déterministe pour le traitement du texte. La notation étendue de correspondance de motifs d’expressions régulières permet notamment
• d’analyser rapidement de grandes quantités de texte pour trouver des motifs de caractères spécifiques
• de découper un texte (une chaîne de caractères) en paragraphes, phrases, mots
• de valider le texte afin de s’assurer qu’il correspond à un modèle prédéfini (par exemple une adresse électronique)
• d’extraire, modifier, remplacer ou supprimer des sous-chaînes de texte
• d’ajouter des chaînes extraites suivant des règles prédéfinies à une collection afin de générer un rapport.
Par exemple, pour vérifier si une chaîne de caractère correspond bien à un fichier.txt, on utilisera l’expression régulière « ^.*\.txt$ », ce qui se décompose en : à partir du début de la chaîne (^), autoriser tout type de caractère un certain nombre de fois (.*), puis le texte doit se terminer par .txt (\.txt$).
Pour trouver toutes les adresses email d’un texte, on implémente l’expression régulière ci-dessous.
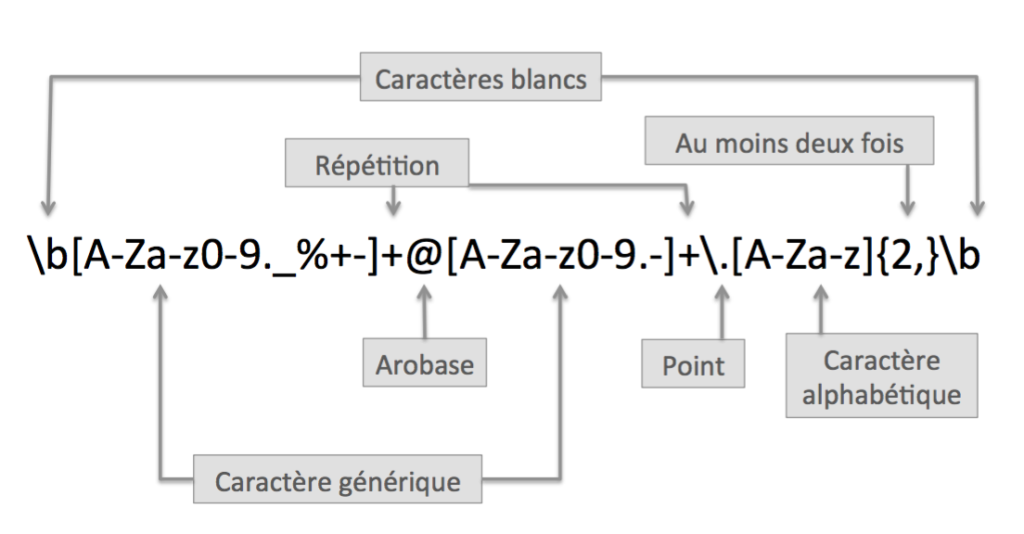
Cette expression régulière signifie : après un caractère blanc (\b), autoriser tout caractère alphanumérique (avec ._%+-) un certain nombre de fois mais au moins une ([A-Za-z0-9._%+-]+), puis le caractère arobase (@), puis des caractères suivis d’un point ([A-Za-z0-9.-]+\.), puis au moins deux caractères alphabétiques ([A-Za-z]{2,}) correspondant à la terminaison (.com ou .fr) et enfin un blanc (\b).
2. Extraire des mots-clés avec TF-IDF
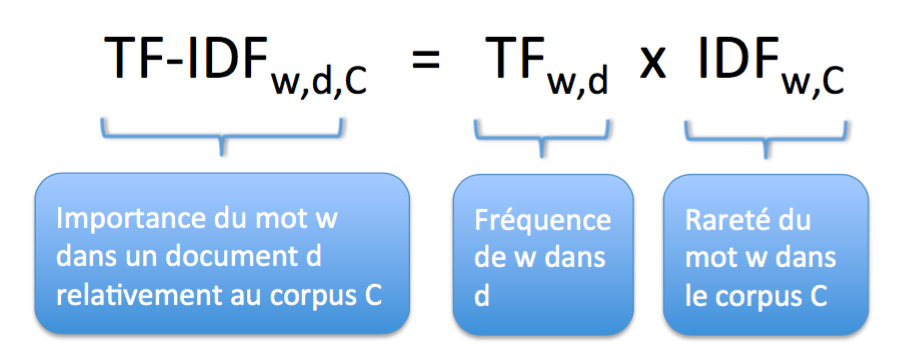
TF-IDF (« term frequency-inverse document frequency ») correspond au premier niveau d’analyse statistique des mots d’un texte, mais il est souvent efficace. Ce poids est une mesure statistique, mais obtenue de manière déterministe, utilisée pour évaluer l’importance d’un mot dans un document faisant partie d’une collection ou d’un corpus de documents. L’importance du mot augmente proportionnellement au nombre de fois que ce mot apparaît dans le document mais est compensé par la fréquence globale du mot dans le corpus.
En effet, plus un mot apparaît dans un document, plus il va caractériser ce document ; mais plus un mot est globalement utilisé dans le corpus, plus sa fréquence habituelle d’apparition est importante (par exemple les mots « et », « le », « à »…), et moins son apparition dans un document précis ne va caractériser ce document. Le poids TF-IDF associé à un mot est donc d’autant plus élevé que le mot est fréquent dans le document considéré et que le mot est rare dans le corpus. Cela permet de détecter facilement les mots-clés (avec TF-IDF élevé) d’un document.
Par exemple, un document que l’on souhaite analyser contient 10 fois le mot « souris » et 50 fois le mot « est ». Si le mot « souris », qui n’est pas très fréquent, n’apparaît que dans 2% des documents du corpus, alors que le mot « est » apparaît dans 50% des documents du corpus, le TF-IDF de « souris » pour le document considéré sera 28 fois1 plus élevé que celui de « est ».
Des variantes de ce système de pondération TF-IDF sont utilisées par les moteurs de recherche pour évaluer et classer la pertinence d’un document en fonction des requêtes des utilisateurs.
3. Modèles de classification de texte
Les modèles de classification sont des modèles de Machine Learning à apprentissage supervisé. Ces modèles fournissent des prédictions de catégorie basées sur un historique d’exemples déjà classifiés, appelé ensemble d’apprentissage. Considérons un exemple tiré du monde bancaire pour illustrer le fonctionnement d’un modèle de classification.
Une banque souhaite prédire par le Machine Learning si des emprunteurs particuliers vont pouvoir rembourser leur emprunt à terme ou non, c’est-à-dire à les classifier en deux catégories « solvable » / « non solvable ». Pour cela elle dispose d’un certain nombre d’informations sur les emprunteurs, caractéristiques démographiques, profils financiers, profils professionnels… ainsi que d’un historique important sur des emprunts passés indiquant si ces emprunts ont été totalement remboursés ou non.
La machine considère itérativement chaque emprunteur de l’historique, puis à l’aide d’un modèle de classification, tente une prédiction « solvable » / « non solvable » de l’emprunteur en fonction de ses caractéristiques. Suivant que la prédiction a été juste ou non, la machine ajuste les coefficients du modèle de classification, et recommence le processus pour un autre emprunteur. Plus le modèle est entraîné sur un nombre important de données (de bonne qualité), meilleure seront les prédictions du modèle, qui peuvent ensuite s’appliquer à de nouveaux emprunteurs, dont on ne sait pas encore la catégorie « solvable » / « non solvable ».
Pour plus de détails sur les modèles de Machine Learning, ou pour d’autres cas d’applications, consulter en particulier le Livre Blanc Myriad « Le Machine Learning, Envol vers le Prédictif ».
En ce qui concerne l’application des modèles de classification à l’analyse des données textuelles, celle-ci peut se décliner de différentes manières suivant le degré de compréhension ciblé du texte (cf Division du NLP).
• Pour l’analyse lexicale, on peut utiliser des modèles de classification « Part-Of-Speech (POS) Tagging ». Ceux-ci permettent à partir des caractéristiques des mots (place dans la phrase, mots précédents et suivants, casse…) de classifier ces mots suivant leur nature grammaticale. Ainsi une phrase comme « une souris a mangé du fromage » devient alors
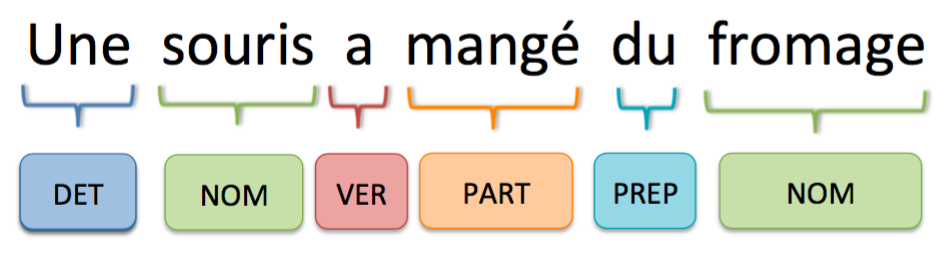
On peut faire remarquer qu’il suffirait d’utiliser un mode déterministe grâce à la constitution d’un référentiel préenregistré donnant pour chaque mot sa nature. Mais, outre qu’il est difficile de construire un référentiel complet, certains mots peuvent avoir une nature différente suivant le contexte et ceci ne sera détecté que par un modèle probabiliste prenant en compte ce contexte. Par exemple, « faible » peut être un nom ou un adjectif, « bien » un nom, un adjectif ou un adverbe…
• Pour l’analyse syntaxique, on peut utiliser des modèles de parsing, qui permettent, à partir du POS Tagging des mots d’une phrase, de les regrouper les mots en groupes et de leur donner une fonction. L’exemple précédent devient alors
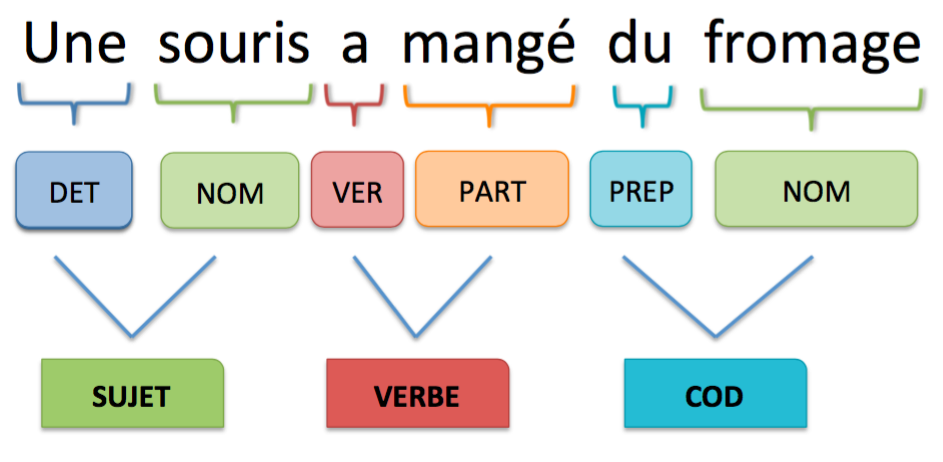
• Pour l’analyse sémantique, on peut utiliser des modèles de classification en « entités nommées » (Named Entity Recognition), qui représentent des catégories importantes de mots pour l’analyse du texte. Cette détection se fait sur des groupes de mots à partir de leurs caractéristiques syntaxiques obtenues à l’étape précédente. Par exemple, il y a la catégorie des entreprises, celle des noms propres, celle des dates, celle des pays, celle des villes…
Ici encore, on peut utiliser des référentiels préenregistrés pour faire cette détection, mais les modèles NER permettent de détecter aussi des mots inconnus au référentiel et de classifier des mots pouvant appartenir à plusieurs catégories suivant le contexte.
• Pour l’analyse de sentiment, on utilise des modèles de classification binaire par rapport à un sentiment du type positivité du propos, objectivité, optimisme, nervosité, ou intérêt. Ces modèles permettent durant l’apprentissage d’associer à chaque mot un coefficient de positivité ou négativité par rapport au sentiment considéré, puis de prédire le sentiment global d’un nouveau texte en sommant les coefficients de tous les mots présents dans ce texte.
Par exemple, si l’apprentissage d’un modèle sur un corpus a permis de déterminer les coefficients pour le sentiment positif/négatif associés aux mots de la phrase « il a apprécié sa chambre mais le service était atroce » comme ci-dessous, le sentiment global de cette phrase sera négatif.

4. Modèles de concepts (WordNet)
Pour aller plus loin dans la compréhension du langage, des linguistes ont recensé les attributs sémantiques des mots du vocabulaire de différentes langues dans des bases de données lexicales. Une des plus connues s’appelle WordNet, construite par l’Université de Princeton. L’identification d’un concept dans un texte se fait alors de manière déterministe par consultation d’une base de données de ce type.
A partir d’un mot – par exemple souris – le modèle permet de déterminer quels sont les différents concepts associés à ce mot, avec leurs différents sens. Chaque concept est codé par un « synset » (synonym set), c’est-à-dire un ensemble de synonymes décrivant chacun le concept. L’intersection des sens de ces synonymes permet de caractériser de manière univoque le concept. Ci-dessous, le mot « souris » est associé à 4 concepts différents, chacun étant listé avec son « synset » et sa définition.

Ces synsets, représentant des concepts, sont regroupés dans des catégories plus générales et abstraites, qui forment ainsi une hiérarchie de concepts appelée ontologie. Il existe d’autres bases de données proposant des ontologies similaires ou plus spécialisées, certaines répertorient aussi les relations pouvant avoir lieu entre des concepts de type différents.
5. Modèles de plongement prédictif de mots (représentation vectorielle)
Les modèles de plongement prédictif de mots, ou « Word Embedding », dont le plus emblématique est Word2Vec, utilisent des réseaux de neurones artificiels pour apprendre statistiquement une représentation vectorielle de chaque mot présent dans le texte. Le vecteur associé à chaque mot prend en compte le contexte dans lequel est apparu ce mot tout au long du texte, ce qui permet d’avoir une représentation numérique encodant des propriétés grammaticales et sémantiques. L’hypothèse sous-jacente est que deux mots seront d’autant plus proches de sens qu’ils apparaissent dans des contextes similaires.
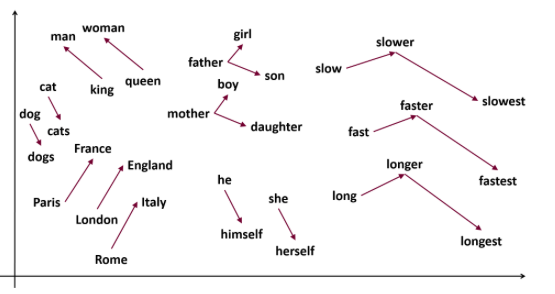
La pertinence de cette représentation dépend évidemment de l’entraînement des modèles – taille du corpus textuel d’apprentissage, qualité de ce corpus, optimisation du paramétrage via des métriques de tests – mais certains résultats sont étonnants de précision. En effet, la représentation vectorielle permet de faire des opérations algébriques, comme l’addition ou la soustraction, aux vecteurs V[w] de chaque mot w.
Par exemple, V[roi]-V[homme]+V[femme] a pour plus proche voisin V[reine] dans un modèle suffisamment entraîné. L’interprétation basique de ce fait peut être la suivante : au concept de roi, on a soustrait le concept de masculinité, et on obtient le concept de royauté. En lui ajoutant le concept de féminité, on obtient alors le concept de reine. Cette représentation par plongement prédictif de mots permet ainsi une compréhension sémantique étonnante des mots d’un texte.
6. Modèles statistiques de langage
Un des buts des modèles statistiques de langage est de construire un modèle qui peut estimer la distribution du langage naturel de manière aussi précise que possible. Un tel modèle correspond donc à une distribution de probabilité sur les chaînes de caractères qui représente la fréquence d’apparition estimée ou « normale » de ces chaînes de caractères en tant que phrase dans un texte.
Un des avantages de ce type de modèles est de fournir un moyen simple de traiter le langage naturel, avec lequel beaucoup d’outils statistiques existent, et qui peut s’adapter à des textes très différents. Un autre avantage réside dans le fait d’utiliser de l’apprentissage non supervisé, c’est-à-dire qu’il n’y a pas besoin de fournir des réponses à l’algorithme, pas de tagging de corpus textuels à faire, mais l’algorithme apprend grâce aux associations statistiques entre les mots.
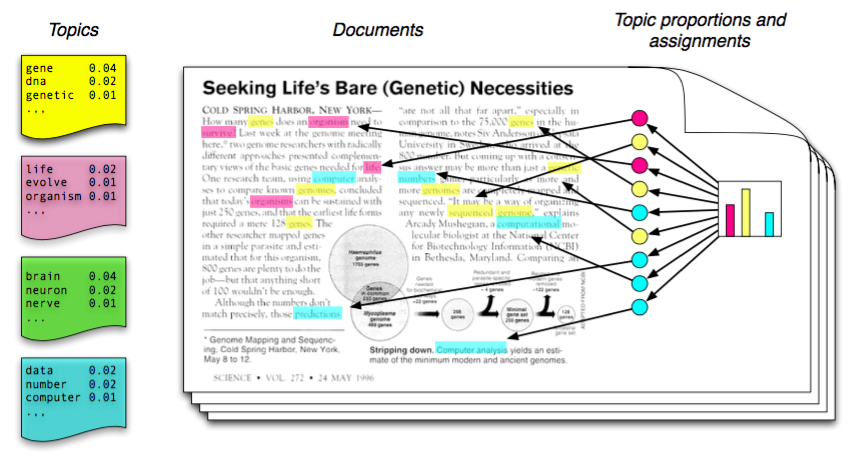
Les modèles de thèmes probabilistes constituent des cas particuliers très utilisés de modèles statistiques de langage. Ceux-ci ont vocation à trouver les thèmes dominants de textes donnés. Les thèmes (ou « topics ») sont eux aussi représentés par des distributions de probabilité qui modélisent la fréquence d’apparition de tel ou tel mot dans un texte associés à ces thèmes. Ceci permet plusieurs choses :
• D’inclure dans un thème non seulement les mots qui le décrivent précisément mais aussi les mots reliés (avec des poids moins élevés)
• De permettre à un mot en particulier d’appartenir à plusieurs thèmes, notamment si ce mot a plusieurs connotations ou sens.
Chaque distribution de probabilité associée à un thème est estimée par des algorithmes statistiques sur des textes que l’on souhaite classifier, puis l’on peut visionner ces thèmes, évaluer leur pertinence, et enfin trouver la proportion de ces thèmes dans d’autres textes. Ces modèles sont donc très intéressants pour avoir une vision globale d’un corpus et en produire une classification thématique.
7. TextRank (Graphes de similarité)
Ce type de modèles, inspiré de l’algorithme PageRank de Google, permet de détecter des groupes de mots caractérisant un texte. Un texte est modélisé par un graphe constitué de nœuds représentant des groupes de mots du texte et d’arêtes représentant la fréquence à laquelle les deux groupes de mots apparaissent ensemble dans le texte.
Le modèle TextRank permet donc un apprentissage non-supervisé, basé sur la statistique d’apparition des mots. Une fois ce graphe construit, des techniques d’analyse de graphes sont appliquées pour déterminer les groupes de mots ayant une centralité plus importante, qui sont alors des candidats de groupes de mots-clés du texte. Plus un groupe de mot est connecté à d’autres (de multiples arêtes partent du nœud associé), et plus ses voisins sont connectés entre eux, plus ce groupe de mots aura alors une centralité élevée.
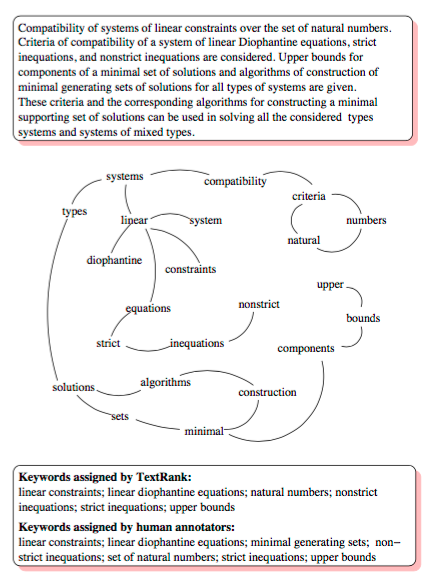
Les possibilités et limites du NLP
Compte-tenu des modèles décrits dans la section précédente et de bien d’autres encore, la question suivante est naturelle : comment mettre tous ces modèles bout à bout et que permettent-ils de faire ?
Les possibilités du NLP peuvent être génériquement regroupées dans le workflow ci-dessous. Chacune de ces possibilités correspond à des tâches qui sont réalisables par des humains à petite échelle ; mais la puissance du NLP réside dans l’automatisation de ces tâches et le déploiement à grande échelle.
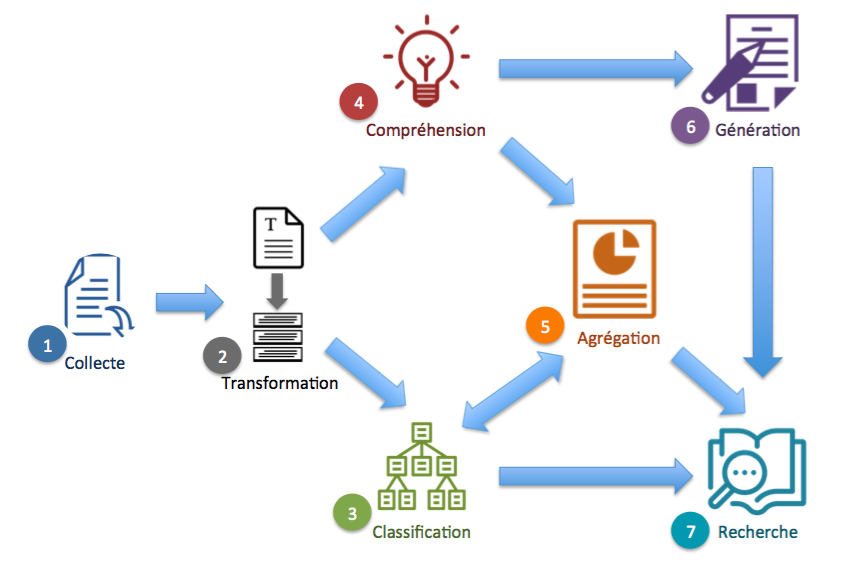
1. Collecte
La collecte de données textuelles se situe plutôt en amont du NLP, mais elle constitue une étape d’importance cruciale pour les modèles NLP qui suivent. Celle-ci inclue des techniques très différentes comme
• Le Web scrapping ou le web crawling, pour la récupération de données textuelles disponibles sur internet
• L’extraction du texte contenu dans des fichiers informatiques comme les formats PDF, MS Word, MS PowerPoint…
• La reconnaissance optique de caractères, dans des fichiers de type image, qui utilise aujourd’hui du Deep Learning
• La conversion de fichiers audio en texte (SpeechToText) qui utilise aussi des techniques de réseaux de neurones artificiels
• L’intégration dans un système GED de gestion électronique des documents au sein d’une entreprise
• La consommation de données textuelles provenant d’API de réseaux sociaux ou de sites d’information (news)
2. Transformation
La partie transformation des données textuelles regroupe des réalités très diverses. Cela concerne tout changement des données par rapport à un but particulier et connu (règle métier), notamment :
• Les prétraitements, nettoyage et standardisation de textes
• La correction orthographique et syntaxique
• La structuration des données par rapport à une structure prédéfinie
• La traduction, qui fait partie des problèmes difficiles appelés « AI-complets », c’est-à-dire nécessitant différents types de connaissances que possèdent les humains (grammaire, sémantique, faits extérieurs sur le monde réel, etc. .)
3. Classification thématique
La classification de documents textuels intervient à un niveau assez haut de compréhension des textes. Il s’agit d’identifier les thèmes globaux de ces textes pour permettre une classification pertinente par rapport à des objectifs métiers.
• Détection de thèmes principaux d’un texte et des mots représentatifs de ces thèmes
• Identification de titres et de mots-clés importants dans un texte
• Regroupement des textes d’un corpus par similarité thématique. Ceci peut être effectué avec un niveau de détails arbitrairement élevé en fonction des besoins
4. Compréhension
Dans la partie compréhension des textes, on peut inclure beaucoup de types d’analyses décrites dans les sections précédentes :
• Analyse lexicale, syntaxique et logique pour une compréhension de la forme
• Analyse sémantique et conceptuelle pour une compréhension du fond, permettant notamment une gestion des synonymes
• Analyse conceptuelle et/ou reconnaissance automatique de catégories (NER) de mots
Cependant, une compréhension fine, et de bout en bout, de textes longs composés de multiples phrases, avec un enchaînement logique complexe, est actuellement hors de portée des algorithmes et constitue un champ de recherche actif et encore ouvert.
5. Agrégation
La partie agrégation concerne les informations générales que l’on peut extraire à partir d’un texte. Elle se nourrit de la partie Classification pour la détection des thèmes et de la partie Compréhension pour la détection des entités nommées (NER). Cela permet notamment
• De produire des résumés automatisés de textes, avec une vision directe des thèmes importants et/ou des mots-clés, sous la forme de tableaux de bord ou de textes grâce à la partie Génération de texte
• De construire des indicateurs sur les textes grâce à de l’analyse de sentiment
6. Génération
Dans cette partie, la machine génère du langage naturel pour faire passer une information ou répondre à une question de manière directement compréhensible par les humains. Cette technique est en particulier très utilisée dans les chatbots. Ceci peut se faire principalement de deux manières
• Mode déterministe : les phrases générées par la machine sont pré-écrites avec certains trous à combler par la machine avec des informations dans sa base de données et elles sont sélectionnées en fonction de ce qui est demandé. Ceci est particulièrement performant dans un périmètre restreint, sur un domaine particulier ou pour répondre à des « FAQs ».
• Mode statistique : les phrases générées par la machine le sont grâce à des modèles probabilistes de langage. En fonction des thèmes considérés, qui sont repérés grâce à la partie Compréhension, une loi de probabilité est déterminée pour la réponse à apporter, à partir de corpus d’apprentissage écrits par des humains, et des mots sont ainsi générés suivant cette loi de probabilité. Cette technique relève encore du domaine de la recherche pour ce qui est de la génération de textes longs et structurés.
D’autre part, pour répondre à une question spécifique, cette technique peut être couplée avec la partie Recherche d’informations, et à partir des mots-clés détectés dans la question, la machine recherche des documents, isole la partie spécifique des documents pertinente pour la question, et peut la restituer/la modifier au demandeur.
7. Recherche d’informations
La recherche d’information permet à un utilisateur de formuler une requête (en langage naturel ou non) et que lui soient restituées des informations pertinentes en regard. Cette requête est, après une partie Compréhension du contenu de la requête, comparée à une base de données propre au système de recherche d’informations.
Cette base de données est donc cruciale pour la pertinence des informations retournées. Elle est constituée de documents qui ont été analysés (cf parties Compréhension et agrégation), dont notamment les mots clés ont été extraits par NER ou TextRank, puis ont été intégrés dans la base de données en tant que métadonnées associées au document considéré. Lorsqu’une requête est effectuée, un score de pertinence avec chaque document de cette base est effectué et les documents les plus pertinents sont retournés à l’utilisateur.

Cas d’applications
Le Natural Language Processing, ainsi que nous l’avons analysé en détail plus haut, permet l’interaction directe homme-machine, et donc d’automatiser nombre de processus/traitements portant sur des données textuelles ou générées par l’homme. Voyons ici quelques cas d’application.
Ressources humaines
• Automatisation de recherche de profils
• Matching CVs – offres de poste
• Construction de référentiels de compétence
• Identification de compétences manquantes et proposition de formation
Réseaux sociaux
• Etudes de tendances (ex : mots buzz)
• Etudes d’image de marques ou de produits
• Analyse des réactions à l’actualité (opinions)
E-commerce
• Recherches des acheteurs basées sur le sens, gestion des synonymes
• Analyse de sentiment dans les commentaires de site web ou forums et Evaluation de la satisfaction client
• Utilisation pour la personnalisation de recommandation produit
Industrie
• Structuration des rapports écrits de Maintenance – renforcement des capacités GMAO
• Analyse de marché/compétition
• Surveillance de la réputation sur internet
• Suivi des règles de conformité produit
Chatbots
• Informer l’utilisateur
• Réponse aux questions
• Améliorer l’image de marque et l’expérience client
Focus sur des applications
Pour mieux comprendre la valeur ajoutée du Natural Language Processing et la combinaison possible des fonctionnalités et algorithmes que nous avons vu plus haut, focalisons-nous sur des retours d’expérience.
Focus 1 : La gestion des compétences en Ressources Humaines
Un grand groupe a souhaité tester les possibilités du Natural Language Processing pour aider ses RH et automatiser certaines tâches dans la gestion interne des talents et dans la partie recrutement.
Enjeux
Le département RH du client faisait face aux enjeux suivants :
• Grand nombre de collaborateurs dont les données sont non structurées
• Grand nombre de postulants chaque année (plusieurs centaines de milliers)
• Grand nombre d’offres de postes à remplir, par des profils internes ou des postulants extérieurs
• Trop de saisie manuelle pour l’exploitation des données non structurées et l’analyse en vue d’un Matching pertinent

Le pipeline utilisé pour l’expérimentation chez ce client suit le schéma ci-dessus. Il regroupe et combine certaines possibilités du NLP vues plus haut :
• la collecte des données textuelles (extraction)
• la transformation de ces données (prétraitements, tagging, structuration)
• leur compréhension (Modélisation sémantique, détection des compétences)
• l’agrégation (construction d’indicateurs)
• la génération (Matching)
• et la recherche d’informations (Mise en place du référentiel de compétences).
Résultats :


Pour aller plus loin :
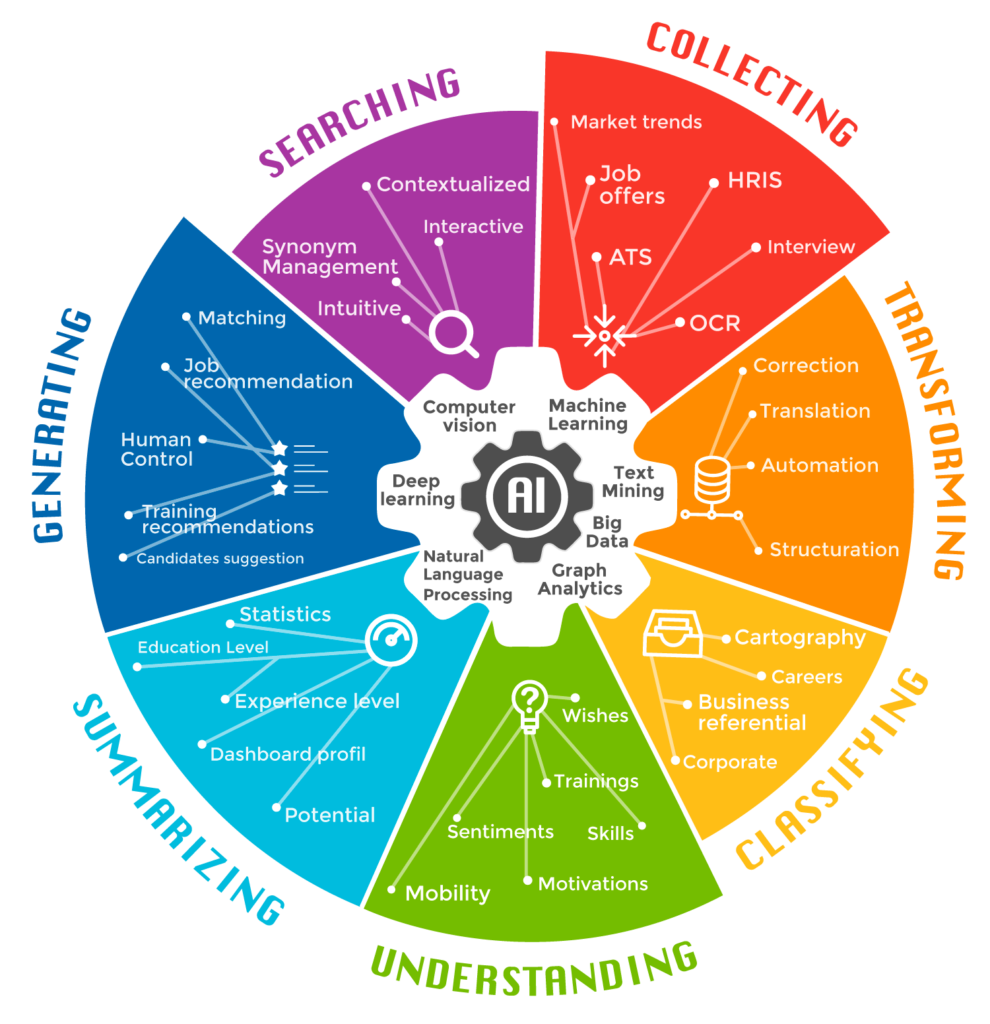
Comme on a pu le constater sur ce point particulier, le NLP permet d’augmenter considérablement l’efficacité RH. Il existe en outre beaucoup d’autres cas d’usage possibles du NLP, combiné à d’autres techniques de l’Intelligence Artificielle, pour le domaine des Ressources Humaines. Le schéma suivant permet d’en avoir un aperçu global.
Focus 2 : La gestion de la maintenance assistée par Intelligence Artificielle
Dans le secteur de l’Industrie et de l’Energie, une des grandes possibilités offertes par l’Intelligence Artificielle est celle de la maintenance prédictive. Cela permet notamment :
• de diagnostiquer en temps réel l’état de fonctionnement de la chaîne de production/l’équipement à surveiller
• d’analyser les risques futurs de défaillance technique et identifier les pièces concernées
• de déterminer en conséquence un plan de maintenance prédictive de l’équipement en minimisant son temps d’arrêt.
Pour alimenter les algorithmes de prédiction, on remonte les données de capteurs connectés, mais une possibilité d’enrichissement de ces données consiste à connecter la GMAO (Gestion de Maintenance Assistée par Ordinateur). Cette base de données contient notamment des données textuelles concernant les événements d’intervention/maintenance sur l’équipement.
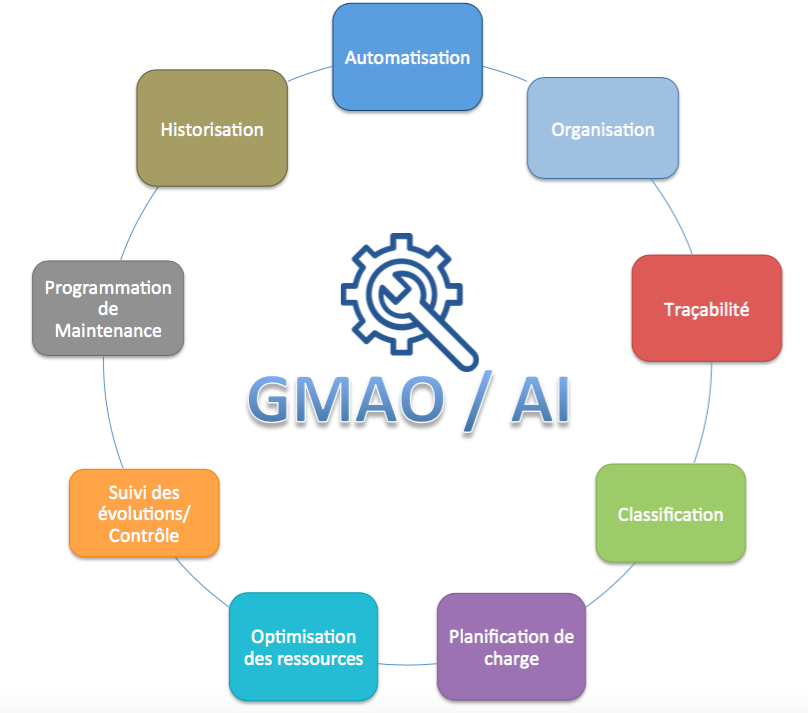
L’utilisation ces données décrivant les événements de maintenance, quand elles sont présentes, est très importante pour les pertinences de prédiction des algorithmes, et ainsi une démarche d’analyse, de compréhension et de structuration de ces données textuelles par le Natural Language Processing s’avère nécessaire.
Par exemple, le Natural Language Processing permet de
repérer et classifier les mots-clés d’un texte décrivant un événement de maintenance : le matériel concerné et son état, le technicien intervenant sur le matériel, le type d’événement, la date…
pouvoir rechercher facilement et corréler ces données une fois classifiées
utiliser ces données, avec d’autres de type capteurs, pour des algorithmes de Machine Learning déterminant un plan de maintenance prédictive.
Focus 3 : L’analyse automatisée de la satisfaction client
A l’heure où l’expérience utilisateur prend tant d’importance et où les méthodes agiles préconisent le co-développement des solutions avec les utilisateurs, la compréhension de la satisfaction client est un enjeu clé pour bon nombre de secteurs d’activité. Le Natural Language Processing permet une automatisation de la détection, l’analyse et la surveillance de cette satisfaction client, de la manière suivante.
• Détermination de sites web clés pour l’étude de la satisfaction client et chargement des contenus via APIs/crawling
• Détection de messages concernant tel produit ou telle marque
• Analyse automatisée du contenu pour déterminer la tonalité et le sentiment du message
• Analyse approfondie pour cibler les caractéristiques appréciées/critiquées
• Agrégation de l’analyse au sein d’un tableau de bord permettant d’avoir une vision globale du produit/de la marque sur les sites ciblés

Focus 4 : Le suivi de la conformité produit
Le Natural Language Processing peut aussi être utilisé pour suivre et comprendre de manière automatique l’évolution des textes légaux, règlementaires, et les normes concernant un produit, ou un secteur d’activité. Ce cas d’usage peut se décliner comme suit
• Collecte des textes légaux ou règlementaires sur le périmètre concerné (produit, secteur), par exemple sur des sites comme Legifrance ou AFNOR.
• Analyse par l’humain des modalités d’expressions des obligations dans ce texte et de leur structure logique
• Choix de textes de référence en tant que corpus d’apprentissage des algorithmes, et tagging de ces textes, en particulier des mots-clés, des catégories importantes de mots, des coordinations logiques
• Implémentation des algorithmes de Natural Language Processing et constitution d’une base de données s’appliquant au périmètre considéré.

Axel de Goursac est directeur des opérations de Myriad. Après avoir été diplômé de l’Ecole Polytechnique et de l’Ecole Normale Supérieure de Paris, il a soutenu en 2009 une thèse de doctorat en Mathématiques et Physique aux Universités de Paris-Sud et de Münster (Allemagne). Puis, il a obtenu un poste de manager de projets de recherche à l’Université Catholique de Louvain et au Fond National de la Recherche scientifique (FNRS, Belgique) en Mathématiques et applications. Passionné de science et de technologie, il est également un chercheur internationalement reconnu et un expert en Machine Learning et Natural Language Processing. Il dirige maintenant le département opérationnel de Myriad.
Myriad
est une société de service qui assure le conseil et le déploiement de solutions d’Intelligence Artificielle et de Big Data. Myriad offre aux Entreprises une véritable expertise dans les domaines analytiques, de Science des Données et d’Architecture. Aujourd’hui, les sociétés reconnaissent qu’il est nécessaire de s’affranchir d’une organisation des données en silos pour en révéler la valeur. Cela suppose de mettre en place une source unique pour les données de l’entreprise, qu’elles soient ou non structurées. Myriad accompagne ses clients dans le cadre de leur transformation vers le Big Data et leur fournit une assistance globale pour l’implémentation de cette transformation, allant d’une stratégie de données claire au Machine et Deep Learning.
Sa spécificité réside à la fois dans une approche sur-mesure, de haut niveau technique, mais aussi résolument orientée business, ainsi que sur une méthode progressive claire “Découvrir/Concevoir/Déployer”, qui permet à ses clients d’avoir le contrôle total de leurs initiatives Big Data et Data Science. Pour assurer la maîtrise des Coûts et du ROI, une approche progressive basée sur des cas d’utilisations réels définis par les métiers est essentielle pour Myriad. Cette approche est un élément clé pour comprendre le business de ses clients, leur permettre de rester à la pointe et élaborer une carte numérique qui transforme leurs données en un véritable avantage compétitif durable.