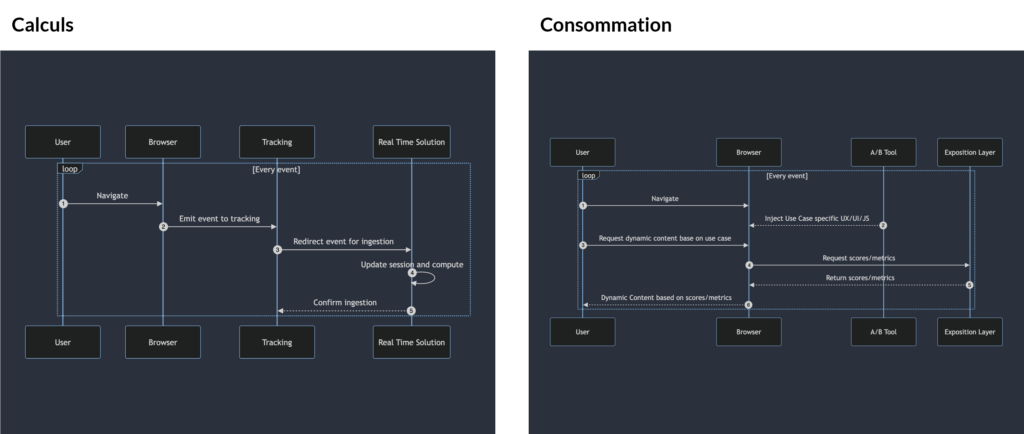
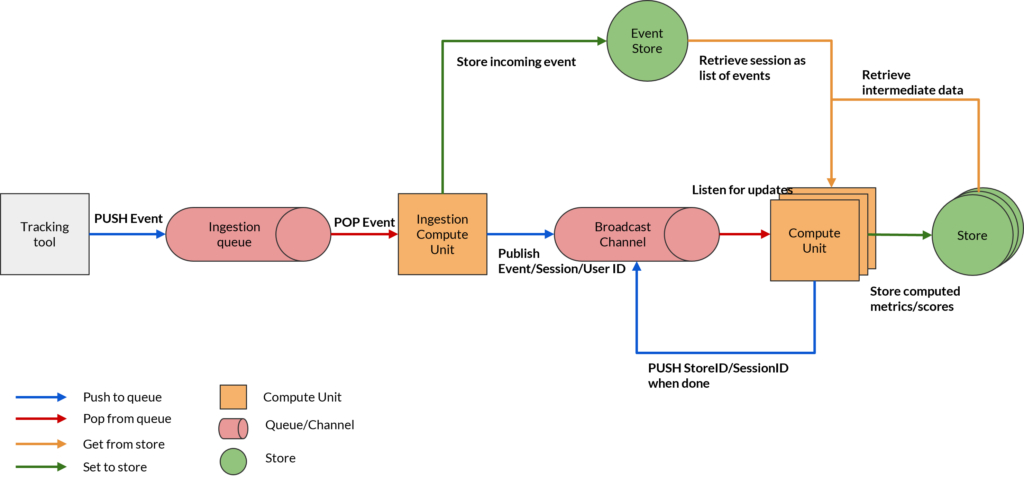
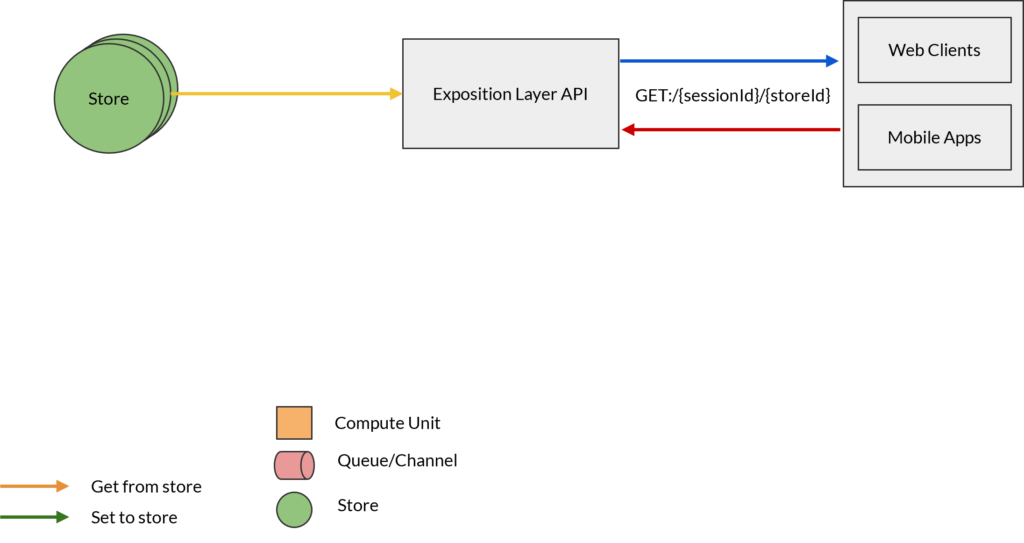
Approche actuelle des cas d'utilisation orientés ML
CONTEXTE
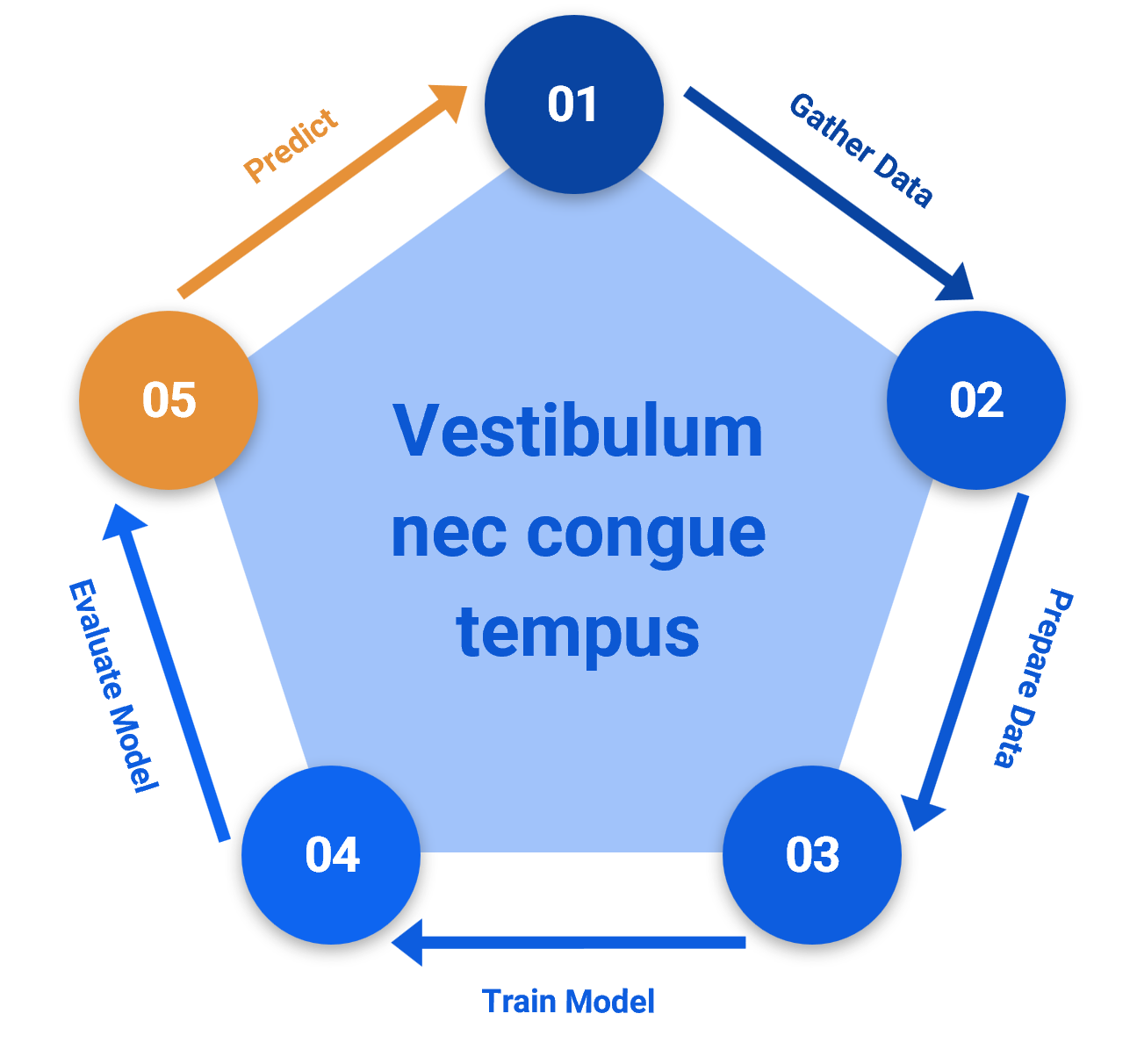
Les modèles historiques d’apprentissage automatique produisaient leurs prédictions par lots pour être utilisés dans différents cas. Ces prédictions pouvaient être rafraîchies périodiquement, mais elles étaient toujours calculées avant le niveau de l’application.
Dans de nombreux cas d’utilisation, les prédictions sont déjà obsolètes lorsqu’elles sont produites en raison des données d’inférence utilisées. L’étape 5 est dans de nombreux cas d’utilisation, en particulier pour le commerce électronique et la vente au détail en ligne, un facteur limitant pour le succès.
Des prévisions statiques aux prévisions dynamiques
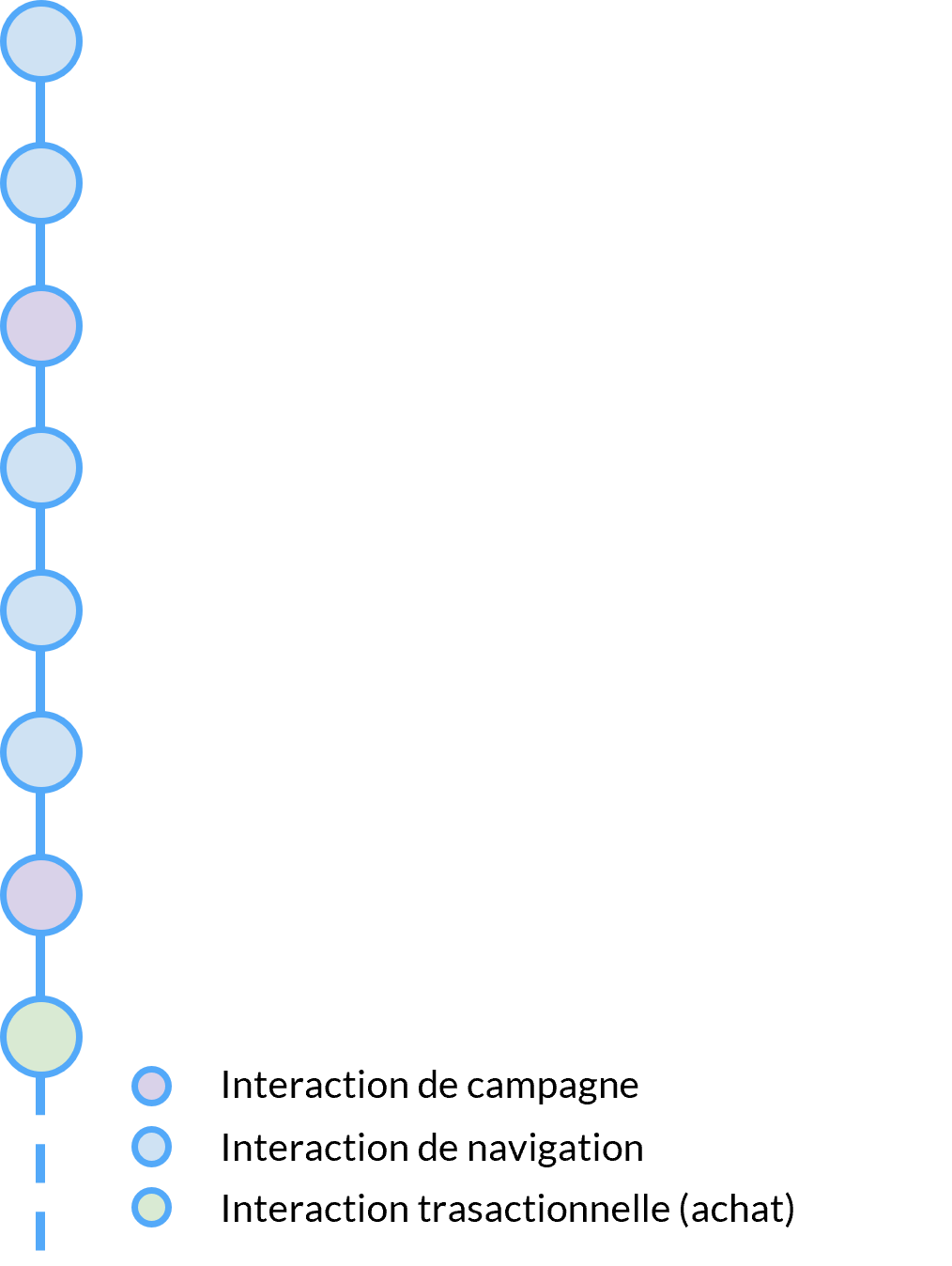
Chaque interaction du client avec votre entreprise est une partie essentielle de son parcours avec votre marque.
Ces interactions peuvent inclure:
des transactions en ligne/hors ligne
des interactions de campagne (ouverture d’email, redirections SMS,…)
la navigation en ligne
La navigation en ligne sur votre plateforme de commerce électronique est une source incroyable d’informations. La plupart du temps, les modèles de ML s’appuient uniquement sur les interactions transactionnelles. Alors que les données de navigation sont abondantes et enrichissent le profil d’un client, elles ne sont pas utilisées.
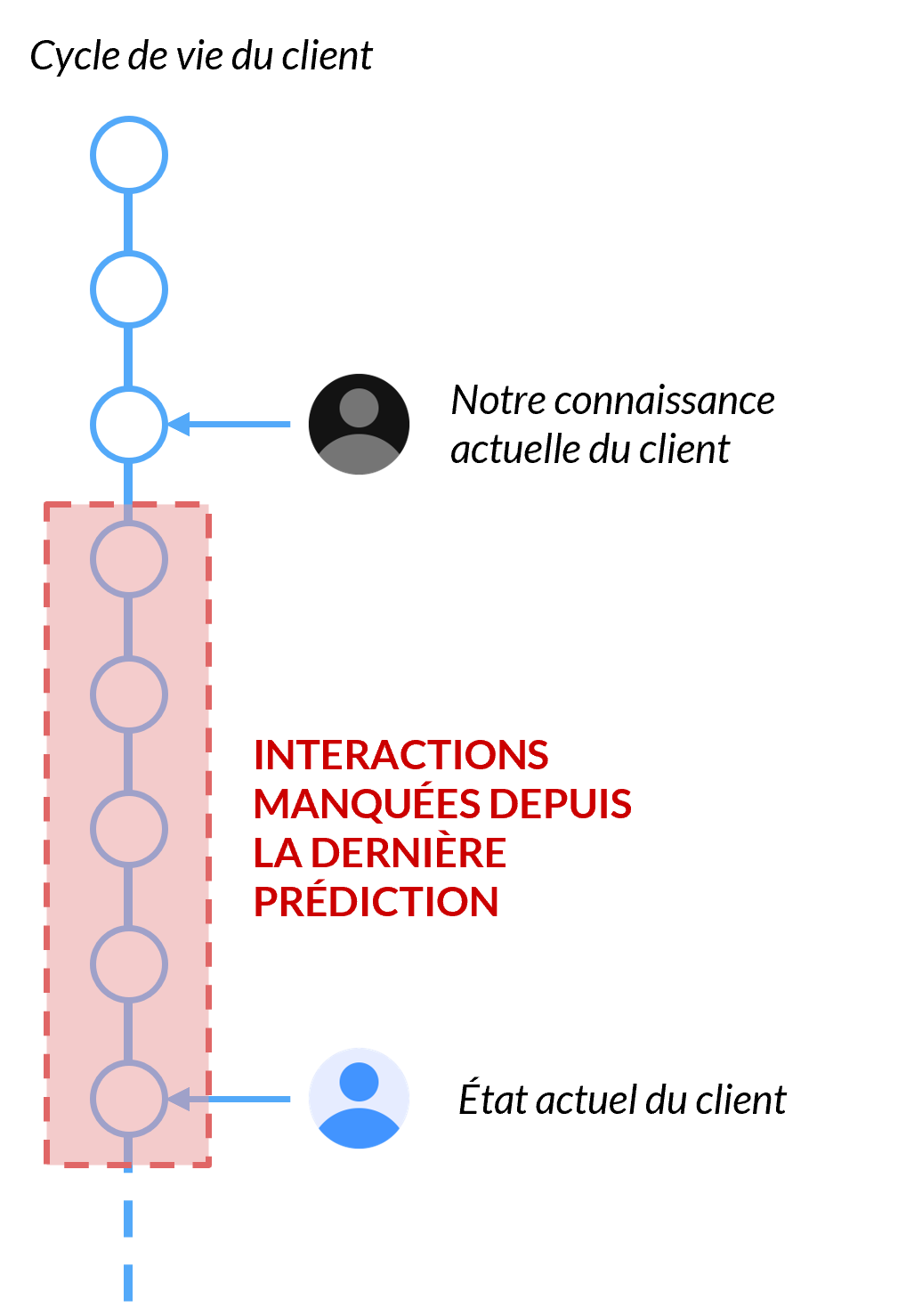
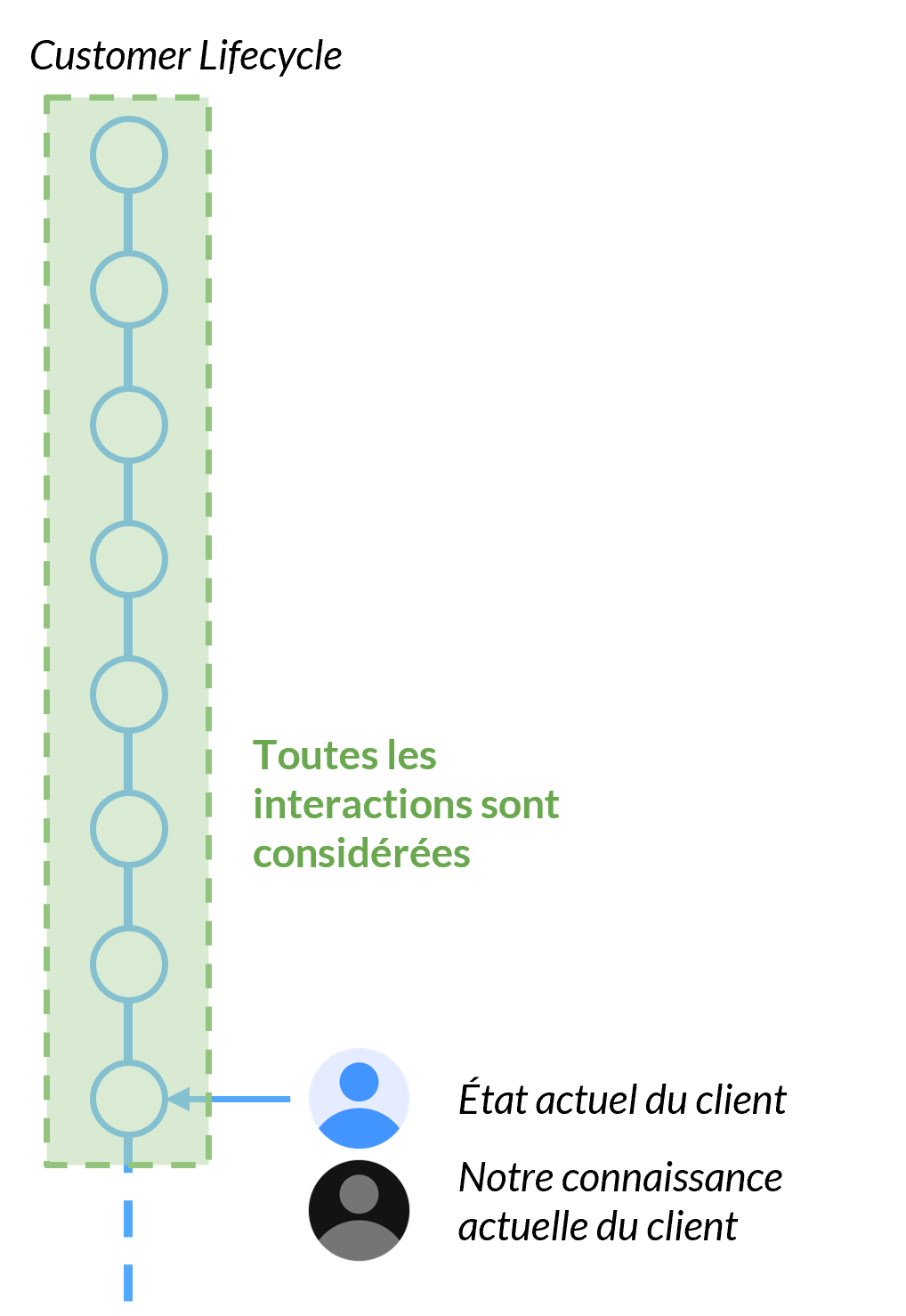
Cycle de vie du client
Cycle de vie du client
Des prévisions statiques aux prévisions dynamiques
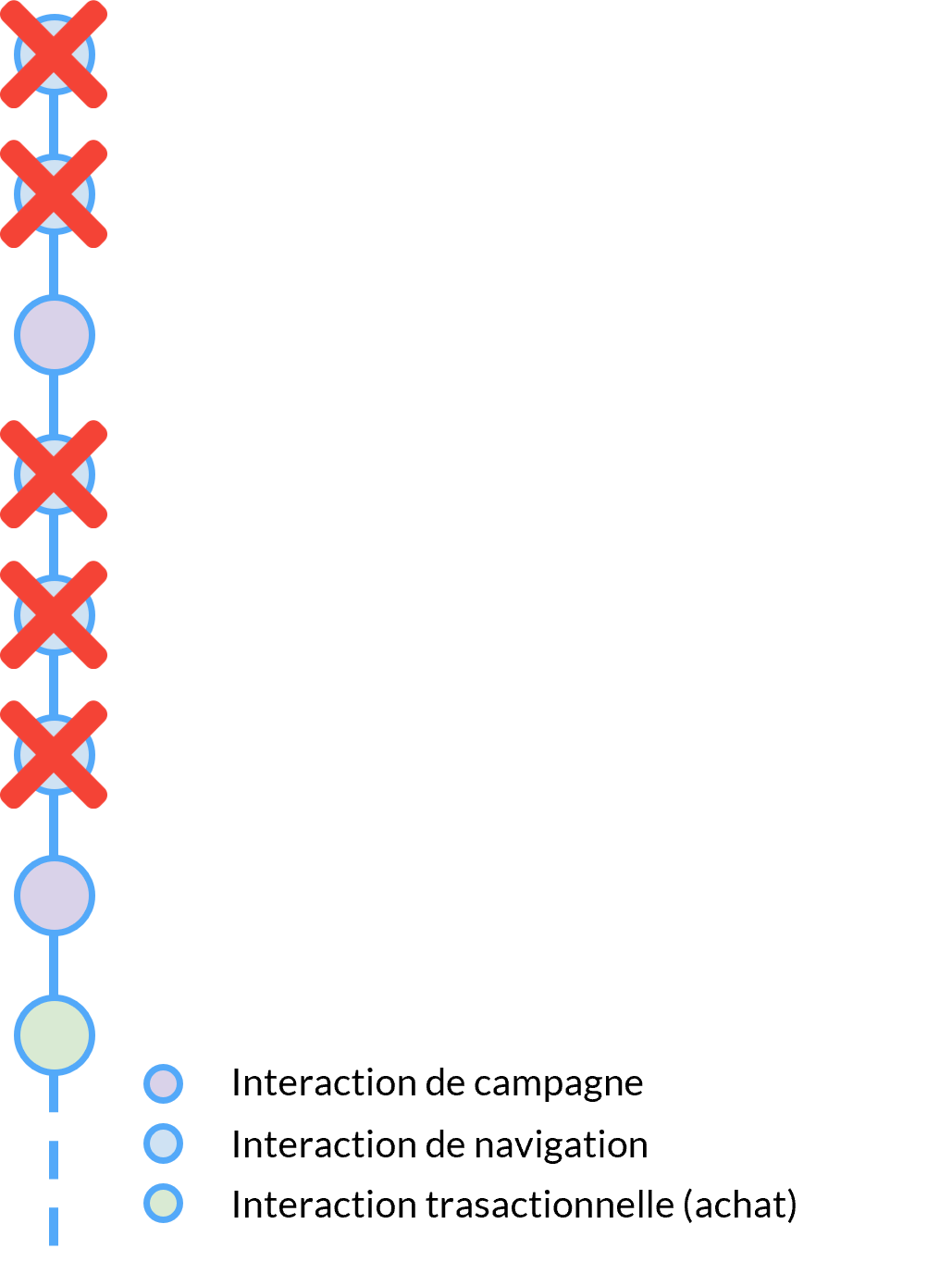
Lors de la formation d’un modèle d’IA, la plupart des informations relatives au comportement et aux préférences du client sont perdues.
Améliorer l'approche centrée sur le client
Les données de navigation sont une mine d’or. Mais même lorsqu’elles sont prises en compte, elles ne résolvent pas les écarts entre notre connaissance du client (CRM, données historiques…) et son état réel.
Sur les plateformes de commerce électronique, où les comportements compulsifs sont la norme, se concentrer sur les interactions passées ne fournit pas suffisamment d’informations pour détecter les intentions éphémères.
Améliorer l'approche centrée sur le client
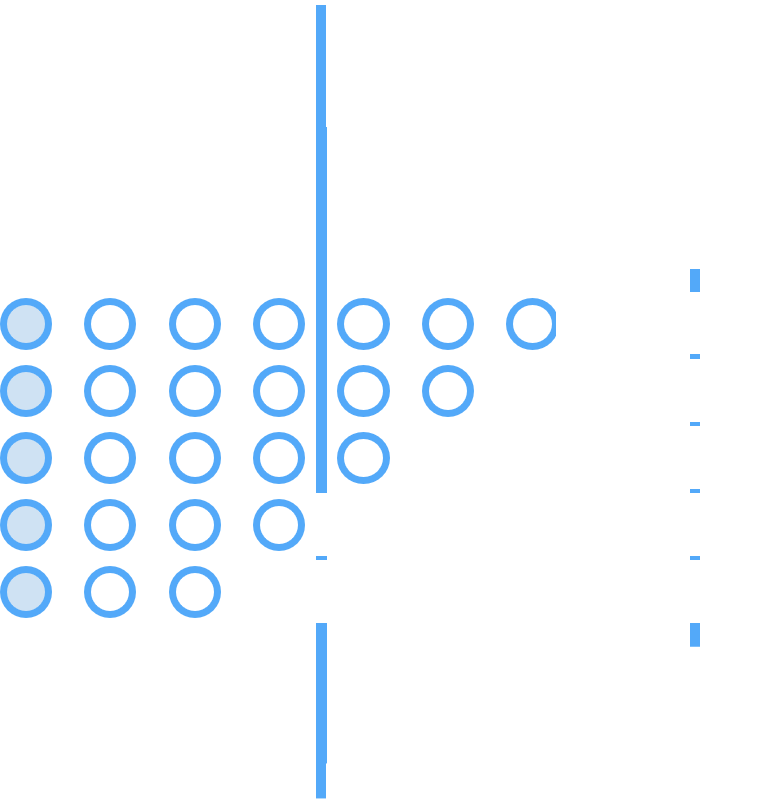
Tout en conservant notre approche centrée sur le client, nous devrions changer notre paradigme pour envisager des modèles d’inférence/prédiction basés sur les sessions.
En passant à une stratégie d’inférence en temps réel, nous serons en mesure de fournir des prédictions plus précises en prenant en compte toutes les interactions.
Typologie des nouveaux cas d‘usages
Cas d’usages
L’IA temps réel permet de nouveaux types de cas d’utilisation sur les sites de commerce électronique. Avec des prédictions statiques générées avant la session, la navigation et le parcours de l’utilisateur sont figés. L’inférence en temps réel permet une navigation dynamique et constitue une première étape vers la personnalisation en ligne en temps réel.
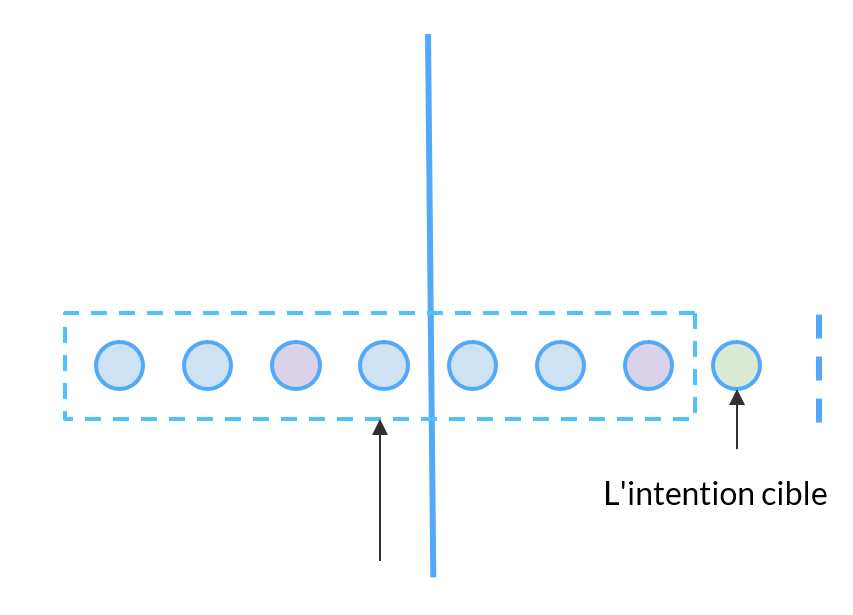
Détection des intentions
Compte tenu de la session de l’utilisateur en cours, nous produisons des scores en temps réel qui catégorisent le comportement en ligne du client et ses intentions. Plus l’intention d’un client est détectée rapidement, plus le niveau de satisfaction est élevé.
Recommendation
Une session de navigation est un processus éphémère. Une session de navigation est un processus éphémère, les besoins du client peuvent changer complètement d’une session à l’autre. Considérer chaque session avec son propre objectif permet de produire des systèmes de recommandation beaucoup plus fins.
Détection de la Frustration
Tous les utilisateurs n’ont pas la même capacité de navigation. Une expérience de navigation claire est indispensable en ligne pour éviter une baisse du taux de conversion. L’évaluation du niveau de frustration par client aide à activer des parcours en ligne pour guider le client.
En analysant le comportement du client (taux de clic, rafraîchissement de la page…) et en regroupant les sessions, nous sommes en mesure de fournir un score dynamique à chaque session. Ce score est actualisé à chaque nouvel événement détecté.
Détection de l'humeur
Les systèmes de recommandation sont indispensables aux plateformes de commerce électronique. Mais même avec de bonnes recommandations basées sur l’historique des interactions avec le client, une session éphémère peut avoir un objectif « aberrant ». Qu’en est-il de la première visite d’un client sur votre site de commerce électronique, où aucune connaissance préalable du client n’existe.
Compte tenu des interactions actuelles avec le client, nous pouvons affiner à chaque événement son intention concernant les produits: Le client cherche-t-il un cadeau ? Pour une occasion spéciale ? Cherche-t-il un type de produit spécifique ?
L’inférence en temps réel permet une telle détection et peut être combinée avec les systèmes de recommandation actuels pour fournir les meilleures recommandations possibles pour une session donnée.
Données de navigation
Les données de navigation sont une source basée sur des événements qui décrivent l’interaction de l’utilisateur avec le site web de commerce électronique.
Les principaux attributs à prendre en compte lors de l’analyse des données de navigation sont l’horodatage (pour ordonner les événements) et l’identifiant de session (pour regrouper les événements dans une session). Une fois ces deux attributs définis dans votre stratégie de suivi, vous pourrez utiliser toutes les informations relatives aux événements dans vos modèles d’apprentissage automatique.
Typologie des caractéristiques
PLONGÉE DANS LES DONNÉES
Alors que les données de navigation offrent une source incroyable d'informations, nous devons garder à l'esprit que l'augmentation de la complexité est corrélée à l'augmentation des temps de calcul. Pour permettre des cas d'utilisation rapides et solides, nous nous concentrons principalement sur 4 types de fonctionnalités
Caractéristiques de l'appareil
Caractéristiques liées à l’appareil, au navigateur et au système d’exploitation pour identifier les appareils discriminants par rapport à une intention donnée.
#Type d’appareil
# Résolution del’écran
# Système d’exploitation…
Caractéristiques de navigation
Caractéristiques liées aux interactions et aux événements de la session pour saisir des modèles pertinents concernant le parcours de l’utilisateur
# Page visitée
# Termes de recherche
# Produit consulté…
Caractéristiques comportementales
Caractéristiques liées à l’intention de l’utilisateur, aux actions, aux fréquences, aux modèles.
# Action par minute
# Temps moyen passé par page
# Intervalle entre les actions…
Caractéristiques
Produits
Caractéristiques liées aux produits/catégories rencontrés au cours de la session
# Catégorie la plus rencontrée
# Prix moyen du produit vu
# Produit le plus cher…
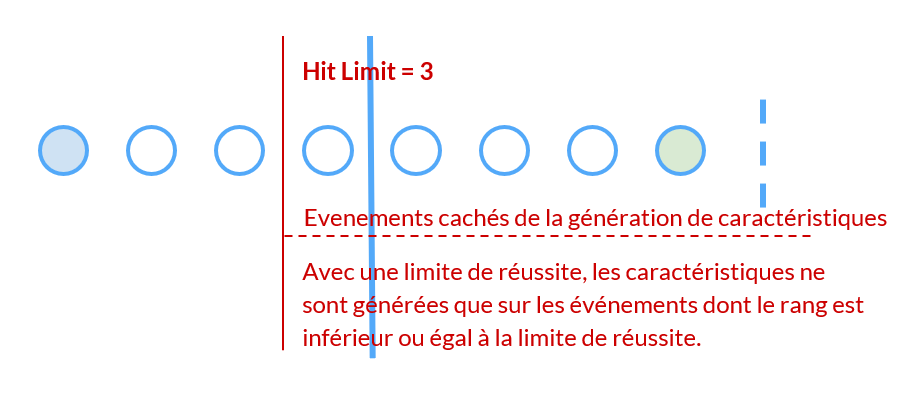
Augmentation des données - Fenêtre élargie
PLONGÉE DANS LES DONNÉES
Alors que les données de navigation offrent une source incroyable d'informations, nous devons garder à l'esprit que l'augmentation de la complexité est corrélée à l'augmentation des temps de calcul. Pour permettre des cas d'utilisation rapides et solides, nous nous concentrons principalement sur 4 types de fonctionnalités
Une astuce intelligente pour rendre votre modèle plus robuste et moins dépendant de la taille de la session consiste à augmenter les données de vos sessions en échantillonnant des sous-sessions.
À partir d’une seule session, nous sommes en mesure de produire plusieurs échantillons. Il est utile d’effectuer l’entraînement du modèle sur des tâches comportant un grand nombre de données déséquilibrées, ce qui permet de rendre le modèle plus robuste et d’améliorer le pouvoir d’anticipation.
Définir votre modèle
Pour des raisons de facilité, nous nous concentrerons sur une tâche de CLASSIFICATION.
Notre modèle doit détecter une intention définie en se basant uniquement sur les données
de navigation.
Chaque session client est composée d’une série d’événements. De ces événements, nous extrayons les caractéristiques de la typologie décrite précédemment.
Evaluer un modèle
Pour des raisons de facilité, nous nous concentrerons sur une tâche de CLASSIFICATION. Notre modèle doit détecter une intention définie en se basant uniquement sur les données de navigation.
Dans le cadre d’une tâche de classification, vous pouvez être familiarisé avec les mesures courantes de performance des modèles :
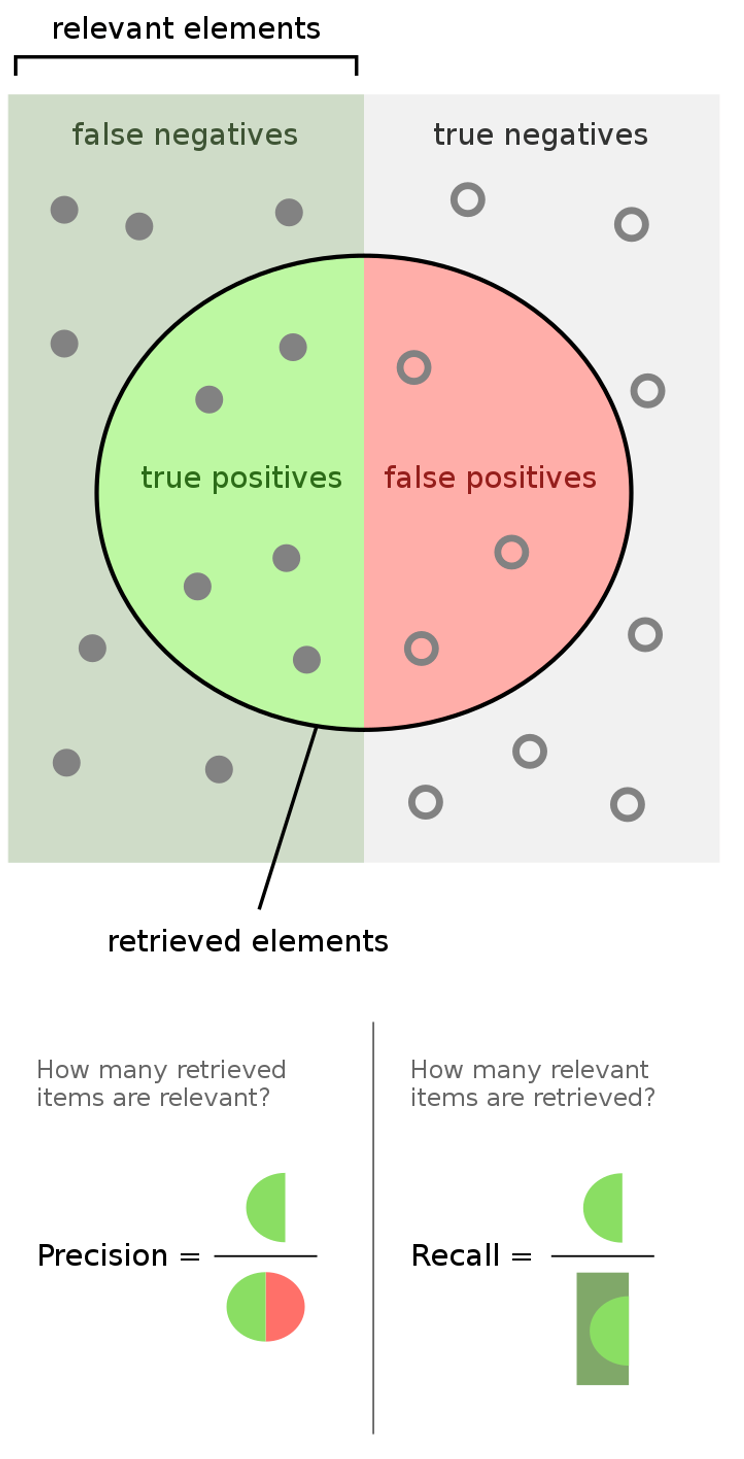
I.Rappel (Quantité)Sur tous les bons échantillons, combien sommes-nous capables de détecter ?
II.Précision (Qualité)Sur tous les échantillons détectés, combien sont bons ?
III.Score F1. En règle générale, la précision et le rappel sont contradictoires. Pour établir une mesure de performance unique, nous utilisons le score F1 comme étant le meilleur compromis entre la précision et le rappel.
Evaluer un modèle- Spécifique au temps réel
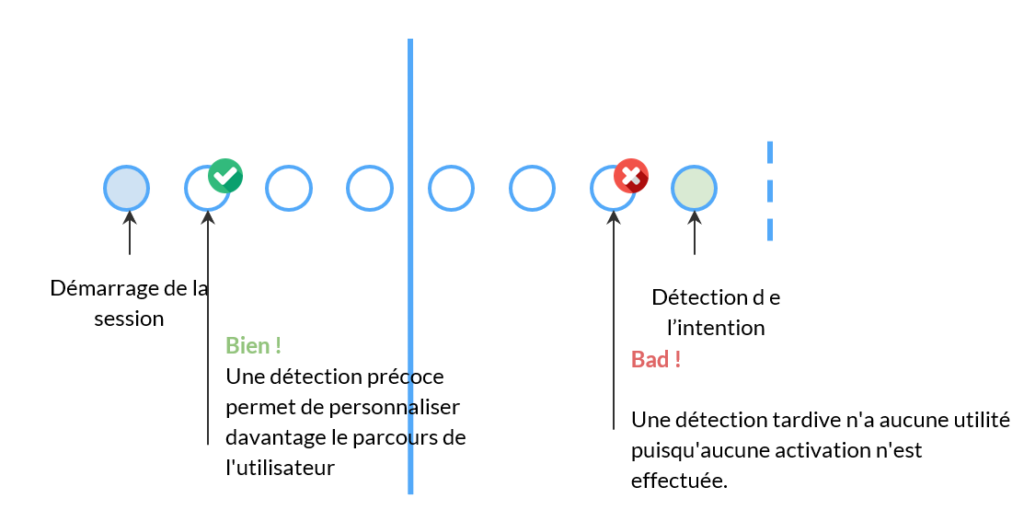
Bien que les mesures de classification habituelles soient toujours pertinentes pour appréhender la performance globale du modèle, elles ne sont pas suffisantes dans le contexte de l’inférence en temps réel.
La détection d’une intention est toujours satisfaisante, mais elle n’a aucune valeur si elle se produit à la fin de la session de l’utilisateur. Nous introduisons le pouvoir de préfiguration comme une mesure permettant d’identifier la capacité du modèle à converger. L’objectif devrait toujours être d’obtenir la détection le plus tôt possible pour permettre l’activation sur site.
Pour chaque session de l’ensemble de données de validation, nous calculons les caractéristiques sur la base d’une fenêtre d’expansion afin d’analyser l’évolution de la détection d’intention en fonction du nombre d’événements.
Evaluer un modèle – L’anticipation (Foreshadowing)
Nous présentons le pouvoir d’anticipation comme une mesure permettant d’identifier la capacité du modèle à converger.
Le pouvoir d’anticipation d’un modèle est calculé sur des échantillons vrais positifs de l’ensemble de données d’évaluation/validation.
Compte tenu des sessions vraies positives, à quel pourcentage de la fin de la session l’intention est-elle détectée ?
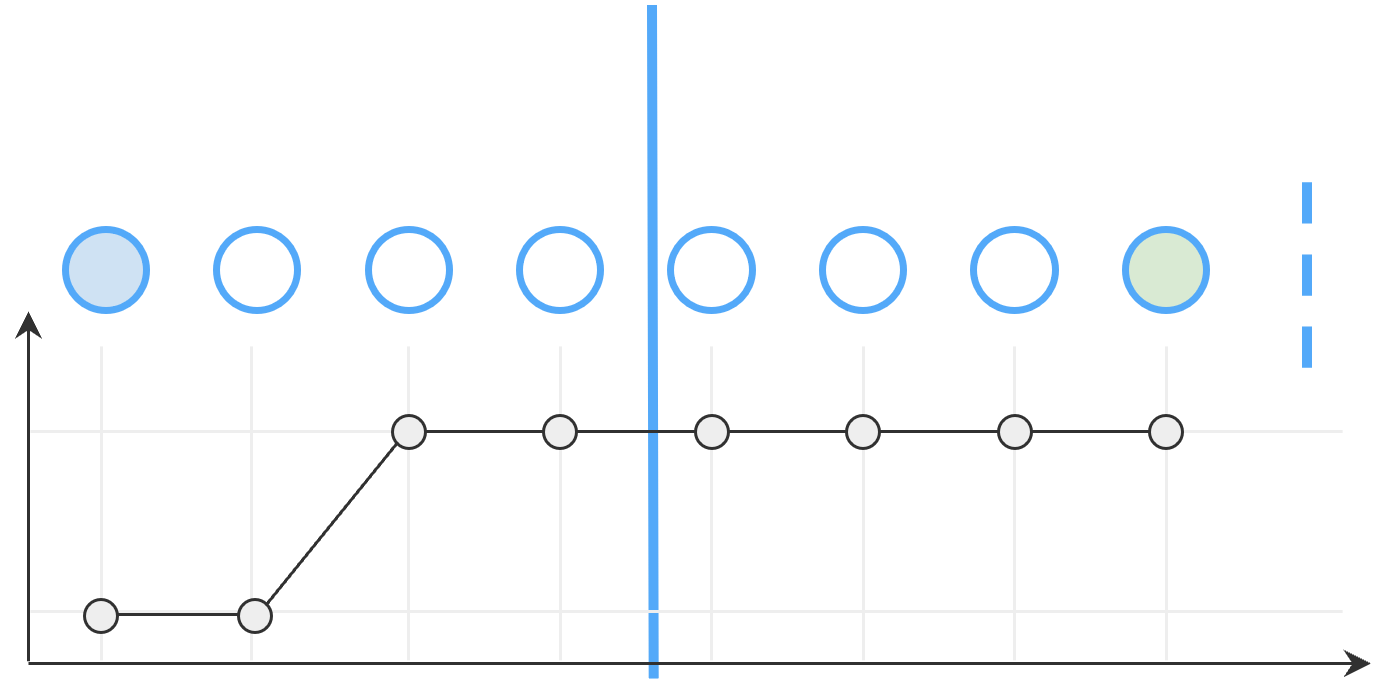
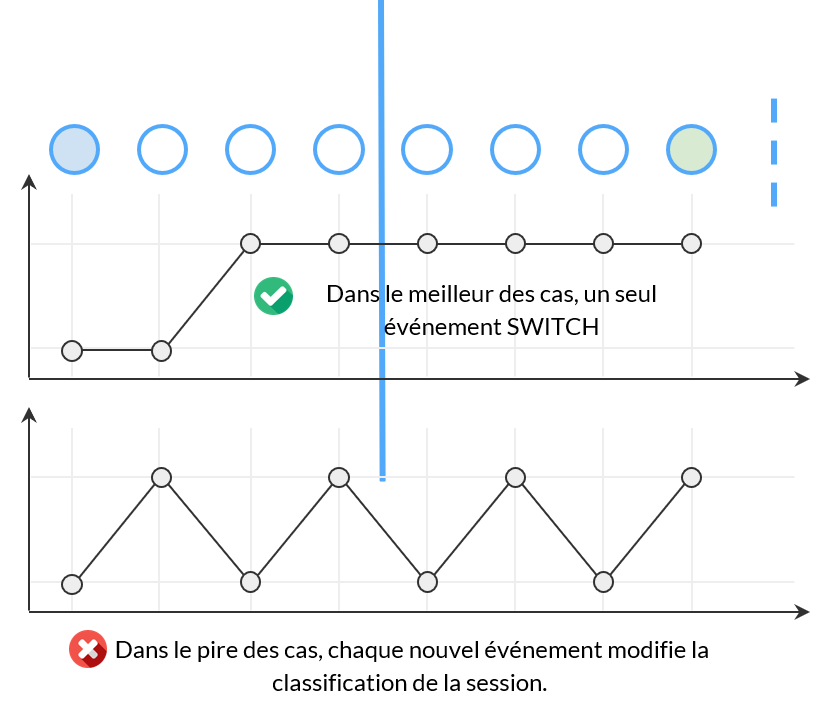
Evaluer un modèle – L’indice de stabilité
Nous introduisons l’indice de stabilité en tant que mesure permettant d’identifier la robustesse du modèle.
Si votre modèle n’est pas robuste au bruit ou trop sensible à la variance supplémentaire, il peut produire des résultats incohérents qui n’auront aucune valeur.
L’indice de stabilité est calculé sur chaque échantillon positif (TP & FP) de l’ensemble de données de validation. Il compte le nombre de changements dans la classification pour l’ensemble de la session.
Il peut également être combiné avec un poids décroissant pour pénaliser plus ou moins les changements précoces ou tardifs.